
Robust træningsdataplatform
ShaipCloud™ bruger patenteret teknologi til at indsamle, spore og overvåge arbejdsbelastninger, transskribere lyd og ytringer, kommentere tekst, billeder og video samt administrere kvalitetskontrol og dataudveksling. Resultatet? Dit AI-projekt får data af den højest mulige kvalitet. Ikke kun får du det hurtigt og til en overkommelig pris, men efterhånden som dit AI-projekt vokser, vokser ShaipCloud™ med det gennem skalerbarhed og platformsintegrationer, der kræves for at gøre dit arbejde lettere og levere succesfulde resultater.

Platformen forenkler arbejdsgangen, reducerer friktionen ved at arbejde med en distribueret global arbejdsstyrke, giver større synlighed og kvalitetskontrol i realtid. Der er dataplatforme. Så er der AI-dataplatforme. Vi er sidstnævnte, fordi den sikre ShaipCloud™ human-in-the-loop platform tilbyder den uovertrufne funktionalitet og hastighed til at indsamle, transformere og kommentere store mængder data (tekst, lyd, billeder og video) for at træne og forbedre AI & ML-algoritmer til NLP- og Computer Vision-brugstilfælde.





Billedsamling
Skab data, der er skræddersyet til ethvert domæne og brugssag gennem vores omfattende netværk af verdensomspændende emneeksperter. Vi tilbyder forskellige billeddatasæt fra flere regioner. Udnyt vores AI-fællesskab til at få adgang til tusindvis af billeder hentet fra lande over hele kloden.

Billedannotation
Vi tilbyder et omfattende udvalg af annotationsstile, der omfatter 2D- og 3D-afgrænsningsfelter, polygonannoteringer, skelsættende identifikation og semantisk segmentering.

Video Collection
Anskaf eller producere videodata skræddersyet til ethvert domæne og brugscase gennem vores omfattende netværk af verdensomspændende emneeksperter. Vi tilbyder forskellige, skuespillerbaserede videoscenarier på flere sprog for at understøtte dine projekter, der dækker en bred vifte af situationer.

Video-kommentar
Annotér videoer effektivt og præcist billede-for-billede med tidsstempler. Brug vores videotransskriptionstjenester til at omdanne lyd til tekst, hvilket forbedrer søgeevnen og tilgængeligheden til SEO-formål.

Indsamling af taledata
Indsaml forskelligartede data i topkvalitet på mere end 150 sprog og dialekter, der omfatter en bred vifte af demografi, såsom køn og alder. Vores data dækker forskellige højttalertræk, dialogtyper – inklusive monologer, samtaler med to højttalere og flere højttalere, såvel som scriptet og spontan tale. Vi leverer også data fra en række forskellige miljøer, såsom hjem, restauranter, callcentre, køretøjer og studieoptagelser, der dækker en bred vifte af scenarier.
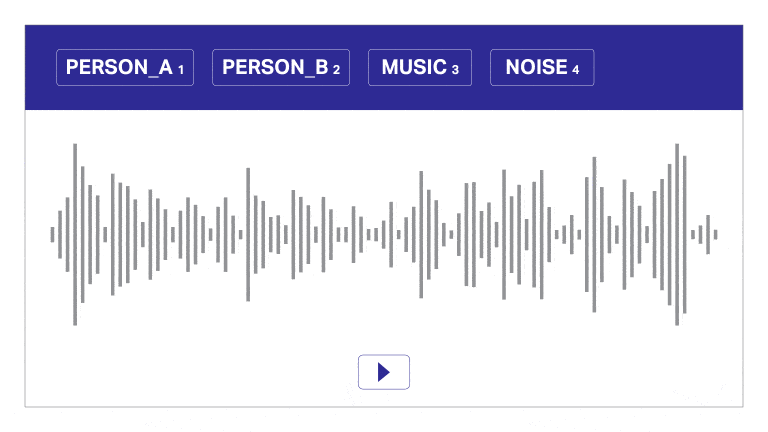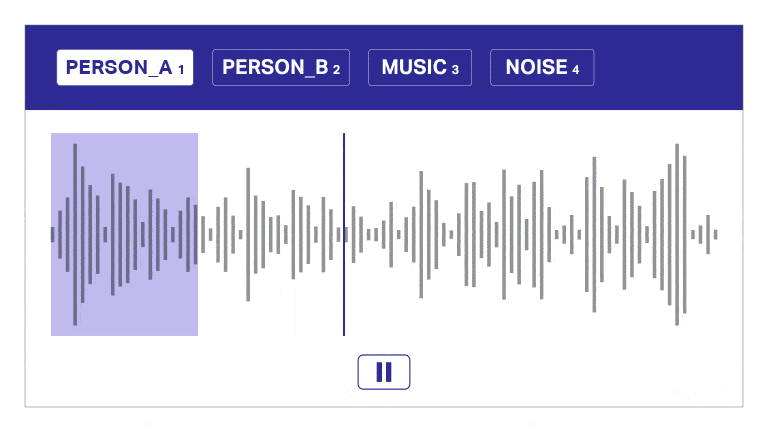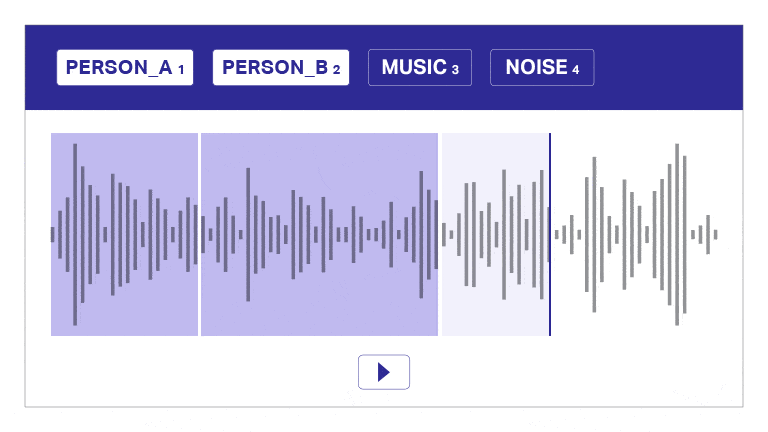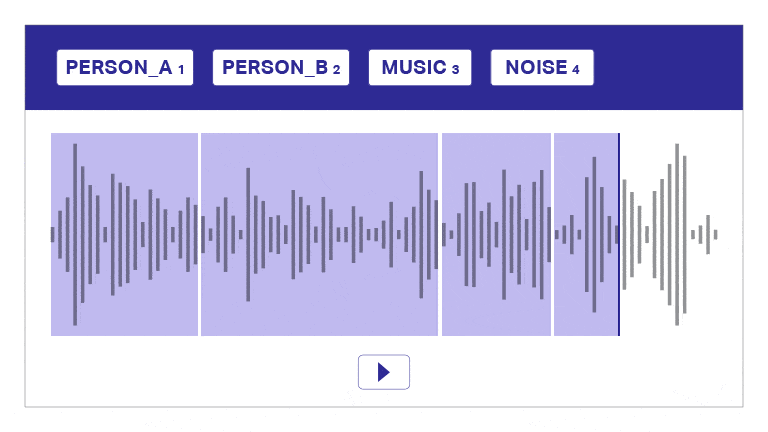
Taledataanmærkning
Vores annoterings- og transskriptionsværktøj segmenterer automatisk lyd i lag, skelner mellem højttalere og giver tidsstempler til effektiv lydkommentarer. Dette brugervenlige værktøj muliggør hurtig og præcis transskription og tidsstempling, hvilket giver mulighed for nøjagtige annoteringer i skala.

Indsamling af tekstdata
Forbedre dine AI-modeller og forstærk deres tilpasningsevne ved at bruge højkvalitets, varierede tekst- og dokumentdata i en bred vifte af sprog og formater, lige fra kvitteringer og online nyhedsartikler til chatbots hensigter og ytringer.

Tekstdataanmærkning
Vores tekstannoteringsværktøjer forenkler processen med at kommentere tekst i dybden, hvilket gør dine modeller i stand til at forstå tekst og udtrække værdifuld indsigt. Derudover leverer vi tjenester til udtrækning af navngivne enheder og entitetsforbindelser for yderligere at forbedre dine tekstanalysemuligheder.




