
Automatiske talegenkendelsessystemer og virtuelle assistenter som Siri, Alexa og Cortana er blevet almindelige dele af vores liv. Vores afhængighed af dem stiger markant, efterhånden som de bliver klogere. Fra at tænde vores lys til at foretage opkald til at skifte tv-kanal, vi udnytter disse smarte teknologier til at udføre hverdagslige opgaver.
Men har du nogensinde undret dig over, hvordan disse talegenkendelsessystemer fungerer?
Nå, denne blog vil uddanne dig om nogle af de grundlæggende principper for automatisk talegenkendelse. Vi vil også undersøge dets funktion, og hvordan funktionelle virtuelle assistenter som Siri er bygget.
Hvad er automatisk talegenkendelse?
Automatic Speech Recognition (ASR) er software, der gør det muligt for computersystemet at konvertere menneskelig tale til tekst ved at udnytte flere kunstig intelligens og maskinlæringsalgoritmer.
Efter konvertering og analyse af den givne kommando, svarer computeren med et passende output for brugeren. ASR blev første gang introduceret i 1962, og siden da har det løbende forbedret sine operationer og fået enormt rampelys på grund af populære applikationer som Alexa og Siri.
Hvad er processen for taleopsamling til træning af ASR-modeller?
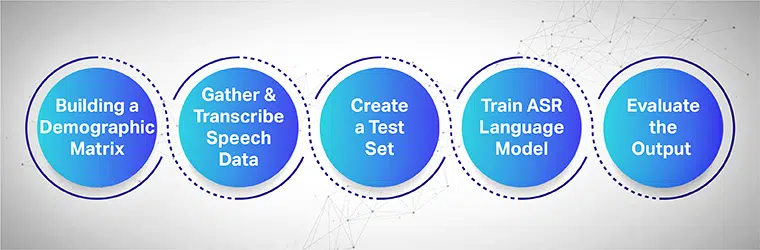
Taleindsamling har til formål at samle flere prøveoptagelser fra flere områder, der bruges til at fodre og træne ASR-modeller. ASR-systemet leverer den højeste effektivitet, når store datasæt af tale og lyd indsamles og leveres til dets system.
For at fungere problemfrit skal de indsamlede taledatasæt indeholde alle måldemografi, sprog, accenter og dialekter. Følgende proces viser, hvordan man træner maskinlæringsmodellen i flere trin:
Start med at bygge en demografisk matrix
Indsamler først og fremmest data for forskellige demografiske grupper såsom placering, køn, sprog, alder og accenter. Sørg også for at fange en række forskellige miljøstøj som gadestøj, venteværelsesstøj, offentlig kontorstøj osv.
Saml og transskriber taledataene
Det næste trin er at indsamle menneskelige lyd- og taleprøver baseret på forskellige geografiske placeringer for at træne din ASR-model. Det er et vigtigt skridt og kræver, at menneskelige eksperter udfører lange og korte ytringer af ord for at få den ægte fornemmelse af sætningen og gentage de samme sætninger med forskellige accenter og dialekter.
Opret et separat testsæt
Når du har samlet den transskriberede tekst, er næste trin at parre den med tilsvarende lyddata. Segmentér derefter dataene yderligere og medtag en erklæring fra dem. Nu, fra de segmenterede datapar, kan du trække tilfældige data fra et sæt til yderligere test.
Træn din ASR-sprogmodel
Jo flere oplysninger dine datasæt har, jo bedre vil din AI-trænede model præstere. Generer derfor flere varianter af tekst og taler, som du har optaget tidligere. Omskriv de samme sætninger ved hjælp af forskellige talenotationer.
Evaluer output og til sidst gentag
Til sidst måler du outputtet af din ASR-model for at rette op på dens ydeevne. Test modellen mod et testsæt for at bestemme dens effektivitet. Det er passende at engagere din ASR-model i en feedback-loop for at generere det ønskede output og rette eventuelle huller.
[Læs også: En omfattende oversigt over automatisk talegenkendelse]

Hvad er de forskellige anvendelsestilfælde af talegenkendelse?
Talegenkendelsesteknologi er meget udbredt i mange brancher i dag. Nogle industrier, der bruger denne enorme teknologi, er som følger:
 Fødevareindustri: Fødevaregiganter som Wendy's og McDonald's er indstillet på at forbedre deres kundeoplevelser ved hjælp af ASR. I mange af deres forretninger har de indsat fuldt funktionelle ASR-modeller til at tage imod bestillinger og videregive dem til madlavningssektionen for at gøre kundeordren klar.
Fødevareindustri: Fødevaregiganter som Wendy's og McDonald's er indstillet på at forbedre deres kundeoplevelser ved hjælp af ASR. I mange af deres forretninger har de indsat fuldt funktionelle ASR-modeller til at tage imod bestillinger og videregive dem til madlavningssektionen for at gøre kundeordren klar.- Telekommunikation: Vodafone er en af de største teleudbydere i verden. Det har designet sine kundepleje- og telefonrelætjenester ved at udnytte ASR-modeller, der guider dig til at løse forskellige forespørgsler og omdirigere dine opkald til berørte afdelinger.
- Rejser og transport: Google Android Auto eller Apple CarPlay er blevet almindelige. De fleste bruger dem til at aktivere navigationssystemer, sende beskeder eller skifte musikafspilningslister. Men med teknologiske fremskridt bliver sådanne systemer mere raffinerede.
BMW Intelligent Personal Assistant lanceret i sin BMW 3-serie er meget smartere end almindelige stemmeassistenter. Det kan gøre det muligt for chauffører at finde bilrelateret information og betjene bilen ved hjælp af stemmekommandoer. - Medier og underholdning: Også mediebranchen bruger ASR i mange af sine projekter. Youtube har lanceret en AI-baseret assistent, der genererer automatiske billedtekster. Mens du taler på skærmen, vil assistenten levere underteksterne for at gøre videoen tilgængelig for en større gruppe af Youtube-brugere.
 Fødevareindustri: Fødevaregiganter som Wendy's og McDonald's er indstillet på at forbedre deres kundeoplevelser ved hjælp af ASR. I mange af deres forretninger har de indsat fuldt funktionelle ASR-modeller til at tage imod bestillinger og videregive dem til madlavningssektionen for at gøre kundeordren klar.
Fødevareindustri: Fødevaregiganter som Wendy's og McDonald's er indstillet på at forbedre deres kundeoplevelser ved hjælp af ASR. I mange af deres forretninger har de indsat fuldt funktionelle ASR-modeller til at tage imod bestillinger og videregive dem til madlavningssektionen for at gøre kundeordren klar. Telekommunikation: Vodafone er en af de største teleudbydere i verden. Det har designet sine kundepleje- og telefonrelætjenester ved at udnytte ASR-modeller, der guider dig til at løse forskellige forespørgsler og omdirigere dine opkald til berørte afdelinger.
Telekommunikation: Vodafone er en af de største teleudbydere i verden. Det har designet sine kundepleje- og telefonrelætjenester ved at udnytte ASR-modeller, der guider dig til at løse forskellige forespørgsler og omdirigere dine opkald til berørte afdelinger. Rejser og transport: Google Android Auto eller Apple CarPlay er blevet almindelige. De fleste bruger dem til at aktivere navigationssystemer, sende beskeder eller skifte musikafspilningslister. Men med teknologiske fremskridt bliver sådanne systemer mere raffinerede.
Rejser og transport: Google Android Auto eller Apple CarPlay er blevet almindelige. De fleste bruger dem til at aktivere navigationssystemer, sende beskeder eller skifte musikafspilningslister. Men med teknologiske fremskridt bliver sådanne systemer mere raffinerede. Medier og underholdning: Også mediebranchen bruger ASR i mange af sine projekter. Youtube har lanceret en AI-baseret assistent, der genererer automatiske billedtekster. Mens du taler på skærmen, vil assistenten levere underteksterne for at gøre videoen tilgængelig for en større gruppe af Youtube-brugere.
Medier og underholdning: Også mediebranchen bruger ASR i mange af sine projekter. Youtube har lanceret en AI-baseret assistent, der genererer automatiske billedtekster. Mens du taler på skærmen, vil assistenten levere underteksterne for at gøre videoen tilgængelig for en større gruppe af Youtube-brugere.
[Læs også: Hvad er tale-til-tekst-teknologi, og hvordan fungerer det]
Hvordan kan Shaip hjælpe?
Shaip er en af de førende AI-træningstjenester, der har ekspertise inden for flere områder af AI og ML. De kan hjælpe dig med at bygge dit eget datasæt, der kan bruges til forskellige applikationer og projekter.
Nogle af de tjenester, der leveres af Shaip er:
- Automatiseret talegenkendelse (ASR)
- Indsamling af scriptet tale
- Transcreation
- Spontan taleindsamling
- Ytringssamling/ Wake-up Words,
- Tekst-til-tale (TTS)
Du kan benytte disse tjenester for at få de bedste resultater for dine AI-baserede projekter. Få mere at vide om disse tjenester ved at kontakte vores ekspertteam i dag!


