
Automatisk talegenkendelse (ASR) er nået langt. Selvom det blev opfundet for længe siden, blev det næsten aldrig brugt af nogen. Men tid og teknologi har nu ændret sig markant. Lydtransskription har udviklet sig væsentligt.
Teknologier som AI (kunstig intelligens) har drevet processen med lyd-til-tekst-oversættelse til hurtige og præcise resultater. Som et resultat er dets applikationer i den virkelige verden også steget, med nogle populære apps som Tik Tok, Spotify og Zoom, der integrerer processen i deres mobilapps.
Så lad os udforske ASR og opdage, hvorfor det er en af de mest populære teknologier i 2022.
Hvad er tale til tekst?
Tale til tekst er en AI-forbedret teknologi, der oversætter menneskelig tale fra en analog til en digital form. Den digitale form af de indsamlede data transskriberes til et tekstformat.
Tale til tekst forveksles ofte med stemmegenkendelse, som er helt anderledes end denne metode. I stemmegenkendelse er fokus på at identificere stemmemønstre hos mennesker, hvorimod systemet i denne metode forsøger at identificere de ord, der bliver sagt.
Almindelige navne på tale til tekst
Denne avancerede talegenkendelsesteknologi er også populær og omtales med navnene:
- Automatisk talegenkendelse (ASR)
- Tale genkendelse
- Computer talegenkendelse
- Lydtransskription
- Skærmlæsning
Forståelse af, hvordan automatisk talegenkendelse fungerer
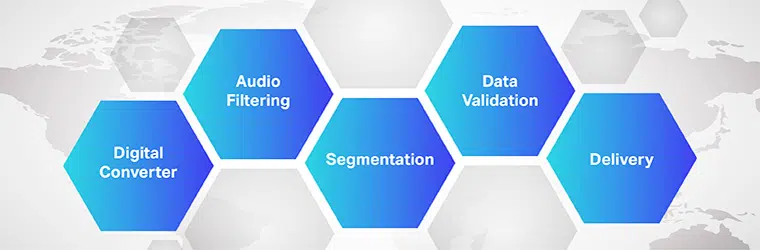
Arbejdet med audio-til-tekst-oversættelsessoftware er komplekst og involverer implementering af flere trin. Som vi ved, er tale-til-tekst en eksklusiv software designet til at konvertere lydfiler til et redigerbart tekstformat; det gør det ved at udnytte stemmegenkendelse.
Proces
- Ved hjælp af en analog-til-digital-konverter anvender et computerprogram i første omgang sproglige algoritmer til de leverede data for at skelne vibrationer fra auditive signaler.
- Dernæst filtreres de relevante lyde ved at måle lydbølgerne.
- Ydermere er lydene fordelt/segmenteret i hundrededele eller tusindedele sekunder og matchet mod fonemer (En målbar lydenhed til at differentiere et ord fra et andet).
- Fonemerne køres yderligere gennem en matematisk model for at sammenligne de eksisterende data med velkendte ord, sætninger og sætninger.
- Outputtet er i en tekst- eller computerbaseret lydfil.
[Læs også: En omfattende oversigt over automatisk talegenkendelse]

Hvad er anvendelsen af tale til tekst?
Der er flere anvendelser af automatisk talegenkendelsessoftware, som f.eks
- Indholdssøgning: De fleste af os har skiftet fra at skrive bogstaver på vores telefoner til at trykke på en knap, så softwaren genkender vores stemme og giver de ønskede resultater.
- Kundeservice: Chatbots og AI-assistenter, der kan guide kunderne gennem de få indledende trin i processen, er blevet almindelige.
- Real-Time Closed Captioning: Med øget global adgang til indhold er undertekster i realtid blevet et fremtrædende og betydningsfuldt marked, der skubber ASR fremad til brug.
- Elektronisk dokumentation: Flere administrationsafdelinger er begyndt at bruge ASR til at opfylde dokumentationsformål, hvilket sørger for bedre hastighed og effektivitet.
Hvad er de vigtigste udfordringer for talegenkendelse?
Lydkommentar har endnu ikke nået toppen af sin udvikling. Der er stadig mange udfordringer, som ingeniørerne forsøger at imødegå for at gøre systemet effektivt, som f.eks
- Få kontrol over accenter og dialekter.
- Forstå konteksten af de talte sætninger.
- Adskillelse af baggrundsstøj for at forstærke inputkvaliteten.
- Skift koden til forskellige sprog for effektiv behandling.
- Analyse af de visuelle signaler, der bruges i talen i tilfælde af videofiler.
Lydtransskriptioner og udvikling af tale-til-tekst AI
Den største udfordring med software til automatisk talegenkendelse er at skabe output 100 % nøjagtigt. Da de rå data er dynamiske, og en enkelt algoritme ikke kan anvendes, er dataene kommenteret for at træne AI til at forstå det i den rigtige sammenhæng.
For at udføre denne proces skal specifikke opgaver implementeres, såsom:
 Navngivet enhedsgenkendelse (NER): NER er processen med at identificere og segmentere forskellige navngivne enheder i specifikke kategorier.
Navngivet enhedsgenkendelse (NER): NER er processen med at identificere og segmentere forskellige navngivne enheder i specifikke kategorier.- Stemnings- og emneanalyse: Softwaren, der bruger flere algoritmer, udfører sentimentanalysen af de leverede data for at give fejlfrie resultater.
 Navngivet enhedsgenkendelse (NER):
Navngivet enhedsgenkendelse (NER): - Hensigts- og samtaleanalyse: Intentionsdetektion har til formål at træne AI til at genkende højttalerens hensigt. Det bruges hovedsageligt til at skabe AI-drevne chatbots.
Konklusion
Tale-til-tekst-teknologi er på et fantastisk stadium i øjeblikket. Med flere digitale enheder, der inkorporerer stemmesøgning og kontrolassistenter i deres apps, er efterspørgslen efter lydtransskription sat til at stige. Hvis du er ivrig efter at tilføje denne imponerende funktion til din app, skal du kontakte Shaips eksperter til indsamling af taledata for at få de fulde detaljer.


