
En robust AI-baseret løsning er bygget på data – ikke bare hvilken som helst data, men højkvalitets, nøjagtigt annoterede data. Kun de bedste og mest raffinerede data kan drive dit AI-projekt, og denne datarenhed vil have en enorm indflydelse på projektets resultat.
Vi har ofte kaldt data for brændstoffet til AI-projekter, men ikke hvilken som helst data duer. Hvis du har brug for raketbrændstof for at hjælpe dit projekt med at nå optur, kan du ikke putte råolie i tanken. I stedet skal data (som brændstof) omhyggeligt raffineres for at sikre, at kun information af højeste kvalitet driver dit projekt. Denne forfiningsproces kaldes dataannotering, og der findes en del vedvarende misforståelser om det.
Definer træningsdatakvalitet i annotering
Vi ved, at datakvalitet gør en stor forskel for resultatet af AI-projektet. Nogle af de bedste og mest højtydende ML-modeller er baseret på detaljerede og nøjagtigt mærkede datasæt.
Men hvordan definerer vi præcis kvalitet i en annotation?
Når vi taler om dataarnnotering kvalitet, nøjagtighed, pålidelighed og konsistens betyder noget. Et datasæt siges at være nøjagtigt, hvis det matcher grundsandheden og oplysninger fra den virkelige verden.
Konsistens af data refererer til niveauet af nøjagtighed, der opretholdes i hele datasættet. Kvaliteten af et datasæt er dog mere præcist bestemt af typen af projekt, dets unikke krav og det ønskede resultat. Derfor bør dette være kriterierne for bestemmelse af datamærkning og annoteringskvalitet.
Hvorfor er det vigtigt at definere datakvalitet?
Det er vigtigt at definere datakvalitet, da det fungerer som en omfattende faktor, der bestemmer kvaliteten af projektet og resultatet.
- Data af dårlig kvalitet kan påvirke produkt- og forretningsstrategierne.
- Et maskinlæringssystem er lige så godt som kvaliteten af data, det trænes på.
- Data af god kvalitet eliminerer efterarbejde og omkostninger forbundet med det.
- Det hjælper virksomheder med at træffe informerede projektbeslutninger og overholder lovgivningsmæssige overholdelse.
Hvordan måler vi træningsdatakvaliteten under mærkning?

Der er flere metoder til at måle træningsdatakvaliteten, og de fleste af dem starter med først at lave en konkret dataannoteringsvejledning. Nogle af metoderne omfatter:
Benchmarks etableret af eksperter
Kvalitets benchmarks eller guldstandard annotation metoder er de nemmeste og mest overkommelige kvalitetssikringsmuligheder, der fungerer som et referencepunkt, der måler projektets outputkvalitet. Den måler dataannoteringerne i forhold til det benchmark, der er fastsat af eksperterne.
Cronbachs alfa-test
Cronbachs alfatest bestemmer korrelationen eller konsistensen mellem datasætelementer. Mærkets pålidelighed og større nøjagtighed kan måles ud fra forskningen.
Konsensusmåling
Konsensusmåling bestemmer niveauet af overensstemmelse mellem maskinelle eller menneskelige annotatorer. Der bør typisk opnås konsensus for hvert punkt og bør afgøres i tilfælde af uenigheder.
Panelgennemgang
Et ekspertpanel bestemmer normalt etikettens nøjagtighed ved at gennemgå dataetiketter. Nogle gange tages en defineret del af dataetiketter normalt som en prøve til at bestemme nøjagtigheden.
Gennemgå Træningsdata Kvalitet
Virksomhederne, der påtager sig AI-projekter, er fuldt ud købt ind i automatiseringens kraft, hvorfor mange fortsat tror, at automatisk annotering-drevet af AI vil være hurtigere og mere præcis end at kommentere manuelt. For nu er virkeligheden, at det tager mennesker at identificere og klassificere data, fordi nøjagtighed er så vigtig. De yderligere fejl, der opstår ved automatisk mærkning, vil kræve yderligere iterationer for at forbedre algoritmens nøjagtighed, hvilket medfører en tidsbesparelse.
En anden misforståelse - og en, der sandsynligvis bidrager til vedtagelsen af automatisk annotering - er, at små fejl ikke har stor indflydelse på resultaterne. Selv de mindste fejl kan producere betydelige unøjagtigheder på grund af et fænomen kaldet AI-drift, hvor inkonsekvenser i inputdata fører en algoritme i en retning, som programmører aldrig havde tænkt sig.
Kvaliteten af træningsdataene – aspekterne af nøjagtighed og konsistens – gennemgås konsekvent for at imødekomme projekternes unikke krav. En gennemgang af træningsdataene udføres typisk ved hjælp af to forskellige metoder –
Automatisk kommenterede teknikker
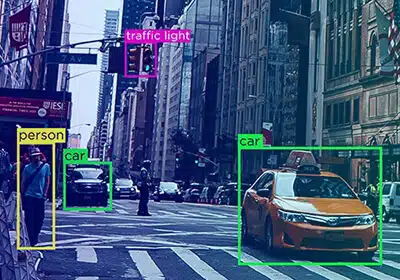 Processen for automatisk annoteringsgennemgang sikrer, at feedback føres tilbage i systemet og forhindrer fejl, så annotatorer kan forbedre deres processer.
Processen for automatisk annoteringsgennemgang sikrer, at feedback føres tilbage i systemet og forhindrer fejl, så annotatorer kan forbedre deres processer.
Automatisk annotering drevet af kunstig intelligens er nøjagtig og hurtigere. Automatisk annotering reducerer den tid, manuelle QA'er bruger på at gennemgå, hvilket giver dem mulighed for at bruge mere tid på komplekse og kritiske fejl i datasættet. Automatisk annotering kan også hjælpe med at opdage ugyldige svar, gentagelser og forkerte annoteringer.
Manuelt via datavidenskabseksperter
Dataforskere gennemgår også dataannoteringer for at sikre nøjagtighed og pålidelighed i datasættet.
Små fejl og unøjagtigheder i annoteringer kan have stor indflydelse på projektets resultat. Og disse fejl bliver muligvis ikke opdaget af værktøjerne til automatisk annoteringsgennemgang. Dataforskere udfører prøvekvalitetstest fra forskellige batchstørrelser for at opdage datainkonsistens og utilsigtede fejl i datasættet.
Bag enhver AI-overskrift er der en kommentarproces, og Shaip kan hjælpe med at gøre det smertefrit
Undgå AI-projekt faldgruber
Mange organisationer er plaget af mangel på interne annoteringsressourcer. Datavidenskabsmænd og ingeniører er i høj efterspørgsel, og at ansætte nok af disse fagfolk til at påtage sig et AI-projekt betyder at skrive en check, der er uden for rækkevidde for de fleste virksomheder. I stedet for at vælge en budgetmulighed (såsom crowdsourcing-annotering), der i sidste ende vil hjemsøge dig, kan du overveje at outsource dine annoteringsbehov til en erfaren ekstern partner. Outsourcing sikrer en høj grad af nøjagtighed og reducerer samtidig de flaskehalse med ansættelser, uddannelse og ledelse, der opstår, når du forsøger at sammensætte et internt team.
Når du outsourcer dine annotationsbehov specifikt med Shaip, benytter du dig af en stærk kraft, der kan fremskynde dit AI-initiativ uden de genveje, der vil gå på kompromis med alle vigtige resultater. Vi tilbyder en fuldt administreret arbejdsstyrke, hvilket betyder, at du kan få langt større nøjagtighed, end du ville opnå ved crowdsourcing -annotationsindsats. Den forudgående investering kan være højere, men det vil betale sig under udviklingsprocessen, når færre iterationer er nødvendige for at opnå det ønskede resultat.
Vores datatjenester dækker også hele processen, herunder sourcing, hvilket er en kapacitet, som de fleste andre mærkningsudbydere ikke kan tilbyde. Med vores erfaring kan du hurtigt og nemt erhverve store mængder geografisk forskelligartede data af høj kvalitet, der er blevet de-identificeret og er i overensstemmelse med alle relevante regler. Når du husker disse data i vores skybaserede platform, får du også adgang til gennemprøvede værktøjer og arbejdsgange, der øger den samlede effektivitet af dit projekt og hjælper dig med at komme hurtigere, end du troede var muligt.
Og endelig vores interne eksperter inden for branchen forstå dine unikke behov. Uanset om du bygger en chatbot eller arbejder på at anvende ansigtsgenkendelsesteknologi til at forbedre sundhedsvæsenet, har vi været der og kan hjælpe med at udvikle retningslinjer, der sikrer, at annoteringsprocessen opnår de mål, der er skitseret for dit projekt.
Hos Shaip er vi ikke bare begejstrede for den nye æra af AI. Vi hjælper det på utrolige måder, og vores erfaring har hjulpet os med at få utallige succesrige projekter fra jorden. Kontakt os for at se, hvad vi kan gøre for din egen implementering anmode om en demo i dag.


