
AI, Big Data og Machine Learning fortsætter med at påvirke politikere, virksomheder, videnskab, mediehuse og en række industrier over hele verden. Rapporter tyder på, at den globale adoptionsrate af AI i øjeblikket er på 35% i 2022 – en stigning på hele 4 % fra 2021. Yderligere 42 % af virksomhederne udforsker efter sigende de mange fordele ved AI for deres forretning.
Styrker de mange AI-initiativer og Maskinelæring løsninger er data. AI kan kun være så god som de data, der fodrer algoritmen. Data af lav kvalitet kan resultere i resultater af lav kvalitet og unøjagtige forudsigelser.
Mens der har været meget opmærksomhed på ML- og AI-løsningsudvikling, mangler bevidstheden om, hvad der kvalificerer sig som et kvalitetsdatasæt. I denne artikel navigerer vi på tidslinjen for kvalitets -AI -træningsdata og identificere fremtiden for kunstig intelligens gennem en forståelse af dataindsamling og træning.
Definition af AI-træningsdata
Når man bygger en ML-løsning, har mængden og kvaliteten af træningsdatasættet betydning. ML-systemet kræver ikke kun store mængder dynamiske, objektive og værdifulde træningsdata, men det har også brug for en masse af det.
Men hvad er AI-træningsdata?
AI-træningsdata er en samling af mærkede data, der bruges til at træne ML-algoritmen til at lave nøjagtige forudsigelser. ML-systemet forsøger at genkende og identificere mønstre, forstå sammenhænge mellem parametre, træffe nødvendige beslutninger og evaluere baseret på træningsdataene.
Tag for eksempel eksemplet med selvkørende biler. Træningsdatasættet for en selvkørende ML-model bør omfatte mærkede billeder og videoer af biler, fodgængere, vejskilte og andre køretøjer.
Kort sagt, for at forbedre kvaliteten af ML-algoritmen har du brug for store mængder velstrukturerede, kommenterede og mærkede træningsdata.
Vigtigheden af kvalitetstræningsdata og deres udvikling
Træningsdata af høj kvalitet er nøgleinput i AI- og ML-appudvikling. Data indsamles fra forskellige kilder og præsenteres i en uorganiseret form, der er uegnet til maskinlæringsformål. Kvalitetstræningsdata – mærket, kommenteret og tagget – er altid i et organiseret format – ideelt til ML-træning.
Kvalitetstræningsdata gør det lettere for ML-systemet at genkende objekter og klassificere dem i henhold til forudbestemte funktioner. Datasættet kan give dårlige modelresultater, hvis klassificeringen ikke er nøjagtig.
De tidlige dage med AI-træningsdata
På trods af at AI dominerede den nuværende forretnings- og forskningsverden, dominerede de tidlige dage før ML Kunstig intelligens var ganske anderledes.
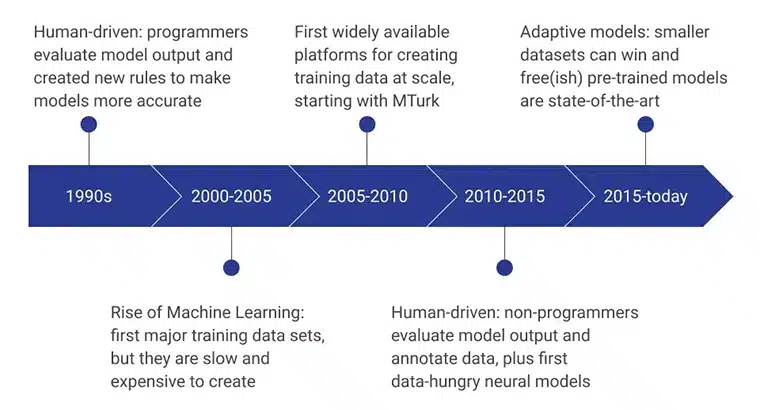
De indledende faser af AI-træningsdata blev drevet af menneskelige programmører, som evaluerede modeloutputtet ved konsekvent at udtænke nye regler, der gjorde modellen mere effektiv. I perioden 2000 – 2005 blev det første større datasæt oprettet, og det var en ekstremt langsom, ressourceafhængig og dyr proces. Det førte til, at træningsdatasæt blev udviklet i stor skala, og Amazons MTurk spillede en væsentlig rolle i at ændre folks opfattelse af dataindsamling. Samtidig tog menneskelig mærkning og annotering også fart.
De næste par år fokuserede på ikke-programmører at skabe og evaluere datamodellerne. I øjeblikket er fokus på præ-trænede modeller udviklet ved hjælp af avancerede træningsdataindsamlingsmetoder.
Mængde i forhold til kvalitet
Ved vurdering af integriteten af AI-træningsdatasæt dengang, fokuserede dataforskere på AI træningsdatamængde over kvalitet.
For eksempel var der en almindelig misforståelse om, at store databaser leverer nøjagtige resultater. Den store mængde data blev anset for at være en god indikator for værdien af data. Kvantitet er kun en af de primære faktorer, der bestemmer værdien af datasættet - rollen som datakvalitet blev anerkendt.
Bevidstheden om at datakvalitet afhang af datafuldstændighed, øget pålidelighed, validitet, tilgængelighed og aktualitet. Vigtigst er det, at dataegnethed til projektet afgjorde kvaliteten af de indsamlede data.
Begrænsninger af tidlige AI-systemer på grund af dårlige træningsdata
Dårlige træningsdata, kombineret med manglen på avancerede computersystemer, var en af årsagerne til adskillige uopfyldte løfter om tidlige AI-systemer.
På grund af manglen på kvalitetstræningsdata kunne ML-løsninger ikke nøjagtigt identificere visuelle mønstre, der stopper udviklingen af neural forskning. Selvom mange forskere identificerede løftet om talesprogsgenkendelse, kunne forskning eller udvikling af talegenkendelsesværktøjer ikke blive til virkelighed takket være manglen på taledatasæt. En anden stor hindring for at udvikle avancerede AI-værktøjer var computernes mangel på beregnings- og lagerkapacitet.
Skiftet til kvalitetstræningsdata
Der skete et markant skift i bevidstheden om, at datasættets kvalitet betyder noget. For at ML-systemet nøjagtigt kan efterligne menneskelig intelligens og beslutningstagningsevner, skal det trives med træningsdata i høj volumen af høj kvalitet.
Tænk på dine ML-data som en undersøgelse – jo større dataprøve størrelse, jo bedre forudsigelse. Hvis prøvedataene ikke inkluderer alle variabler, genkender de muligvis ikke mønstre eller bringer unøjagtige konklusioner.
Fremskridt inden for AI-teknologi og behovet for bedre træningsdata
 Fremskridtene inden for AI-teknologi øger behovet for kvalitetstræningsdata.
Fremskridtene inden for AI-teknologi øger behovet for kvalitetstræningsdata.Forståelsen af, at bedre træningsdata øger chancen for pålidelige ML-modeller, gav anledning til bedre dataindsamling, annotering og mærkningsmetoder. Kvaliteten og relevansen af dataene påvirkede direkte kvaliteten af AI-modellen.
 Fremskridtene inden for AI-teknologi øger behovet for kvalitetstræningsdata.
Fremskridtene inden for AI-teknologi øger behovet for kvalitetstræningsdata.Øget fokus på datakvalitet og nøjagtighed
For at ML-modellen kan begynde at give nøjagtige resultater, er den fodret på kvalitetsdatasæt, der gennemgår iterative dataraffineringstrin.
For eksempel kan et menneske være i stand til at genkende en bestemt hunderace inden for få dage efter at være blevet introduceret til racen - gennem billeder, videoer eller personligt. Mennesker trækker på deres erfaringer og relateret information til at huske og trække denne viden frem, når det er nødvendigt. Alligevel virker det ikke så let for en maskine. Maskinen skal fodres med tydeligt annoterede og mærkede billeder - hundreder eller tusinder - af den pågældende race og andre racer, for at den kan oprette forbindelsen.
En AI-model forudsiger resultatet ved at korrelere den trænede information med informationen præsenteret i virkelige verden. Algoritmen gøres ubrugelig, hvis træningsdataene ikke indeholder relevant information.
Vigtigheden af forskelligartede og repræsentative træningsdata
Øget datadiversitet øger også kompetencen, reducerer bias og øger en retfærdig repræsentation af alle scenarier. Hvis AI-modellen trænes ved hjælp af et homogent datasæt, kan du være sikker på, at den nye applikation kun vil fungere til et bestemt formål og tjene en bestemt population.Et datasæt kan være forudindtaget mod en bestemt befolkning, race, køn, valg og intellektuelle meninger, hvilket kan føre til en unøjagtig model.
Det er vigtigt at sikre, at hele dataindsamlingsprocesflowet, herunder valg af emnepulje, kuration, annotering og mærkning, er tilstrækkeligt forskelligartet, afbalanceret og repræsentativt for befolkningen.
 Øget datadiversitet øger også kompetencen, reducerer bias og øger en retfærdig repræsentation af alle scenarier. Hvis AI-modellen trænes ved hjælp af et homogent datasæt, kan du være sikker på, at den nye applikation kun vil fungere til et bestemt formål og tjene en bestemt population.
Øget datadiversitet øger også kompetencen, reducerer bias og øger en retfærdig repræsentation af alle scenarier. Hvis AI-modellen trænes ved hjælp af et homogent datasæt, kan du være sikker på, at den nye applikation kun vil fungere til et bestemt formål og tjene en bestemt population.Fremtiden for AI-træningsdata
AI-modellernes fremtidige succes afhænger af kvaliteten og kvantiteten af træningsdata, der bruges til at træne ML-algoritmerne. Det er afgørende at erkende, at dette forhold mellem datakvalitet og kvantitet er opgavespecifikt og ikke har noget entydigt svar.
I sidste ende er tilstrækkeligheden af et træningsdatasæt defineret af dets evne til at yde pålideligt godt til det formål, det er bygget.
Fremskridt inden for dataindsamling og annoteringsteknikker
Da ML er følsom over for de tilførte data, er det afgørende at strømline dataindsamling og annoteringspolitikker. Fejl i dataindsamling, kurering, forkert fremstilling, ufuldstændige målinger, unøjagtigt indhold, dataduplikering og fejlagtige målinger bidrager til utilstrækkelig datakvalitet.
Automatiseret dataindsamling gennem data mining, web-scraping og dataekstraktion baner vejen for hurtigere datagenerering. Derudover fungerer færdigpakkede datasæt som en hurtig-fix-dataindsamlingsteknik.
Crowdsourcing er en anden banebrydende metode til dataindsamling. Mens rigtigheden af dataene ikke kan stå inde for, er det et glimrende værktøj til at indsamle offentligt billede. Endelig specialiseret dataindsamling eksperter leverer også data hentet til specifikke formål.
Øget vægt på etiske overvejelser i træningsdata
Med de hurtige fremskridt inden for kunstig intelligens er der dukket flere etiske spørgsmål op, især inden for træningsdataindsamling. Nogle etiske overvejelser ved indsamling af træningsdata omfatter informeret samtykke, gennemsigtighed, bias og databeskyttelse.Da data nu omfatter alt fra ansigtsbilleder, fingeraftryk, stemmeoptagelser og andre kritiske biometriske data, bliver det kritisk vigtigt at sikre overholdelse af juridisk og etisk praksis for at undgå dyre retssager og skade på omdømme.
Potentialet for endnu bedre kvalitet og forskelligartede træningsdata i fremtiden
Der er et kæmpe potentiale for forskelligartede træningsdata af høj kvalitet i fremtiden. Takket være bevidstheden om datakvalitet og tilgængeligheden af dataudbydere, der imødekommer kvalitetskravene til AI-løsninger.
Nuværende dataudbydere er dygtige til at bruge banebrydende teknologier til etisk og lovligt at skaffe massive mængder af forskellige datasæt. De har også interne teams til at mærke, kommentere og præsentere data tilpasset til forskellige ML-projekter.
 Med de hurtige fremskridt inden for kunstig intelligens er der dukket flere etiske spørgsmål op, især inden for træningsdataindsamling. Nogle etiske overvejelser ved indsamling af træningsdata omfatter informeret samtykke, gennemsigtighed, bias og databeskyttelse.
Med de hurtige fremskridt inden for kunstig intelligens er der dukket flere etiske spørgsmål op, især inden for træningsdataindsamling. Nogle etiske overvejelser ved indsamling af træningsdata omfatter informeret samtykke, gennemsigtighed, bias og databeskyttelse.Konklusion
Det er vigtigt at samarbejde med pålidelige leverandører med en akut forståelse af data og kvalitet til udvikle avancerede AI-modeller. Shaip er den førende annoteringsvirksomhed, der er dygtig til at levere skræddersyede dataløsninger, der opfylder dine AI-projektbehov og -mål. Partner med os og udforsk de kompetencer, engagement og samarbejde, vi bringer til bordet.


