Store sprogmodeller har for nylig vundet massiv fremtræden, efter at deres yderst kompetente use case ChatGPT blev en succes fra den ene dag til den anden. Efter at have set succesen med ChatGPT og andre ChatBots er et væld af mennesker og organisationer blevet interesseret i at udforske teknologien, der driver sådan software.
Store sprogmodeller er rygraden bag denne software, der gør det muligt at arbejde med forskellige Natural Language Processing-applikationer som maskinoversættelse, talegenkendelse, besvarelse af spørgsmål og tekstresumé. Lad os lære mere om LLM, og hvordan du kan optimere det til de bedste resultater.
Hvad er store sprogmodeller eller ChatGPT?
Store sprogmodeller er maskinlæringsmodeller, der udnytter kunstige neurale netværk og store siloer af data til at drive NLP-applikationer. Efter træning i store mængder data, opnår LLM evnen til at fange forskellige kompleksiteter af naturligt sprog, som det yderligere udnyttede til:
- Generering af ny tekst
- Sammenfatning af artikler og passager
- Udtræk af data
- Omskrivning eller omskrivning af teksten
- Klassificering af data
Nogle populære eksempler på LLM er BERT, Chat GPT-3 og XLNet. Disse modeller er trænet på hundredvis af millioner af tekster og kan give værdifulde løsninger på alle typer af forskellige brugerforespørgsler.
Populære eksempler på store sprogmodeller
Her er nogle af de bedste og mest udbredte brugssager af LLM:
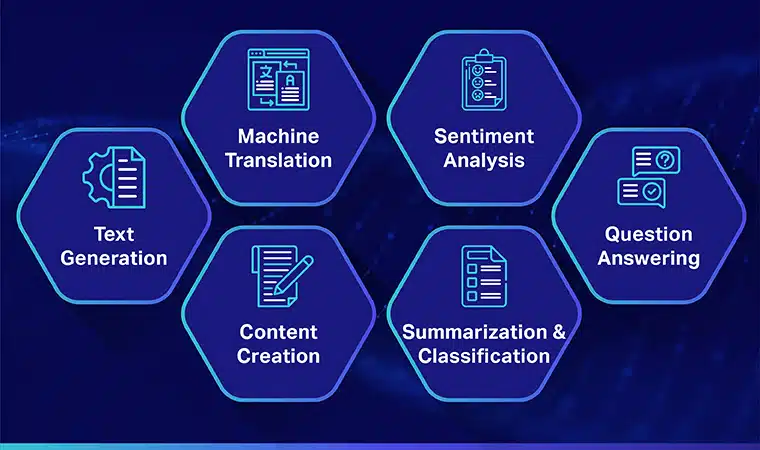
Tekstgenerering
Store sprogmodeller udnytter kunstig intelligens og datalingvistisk viden til automatisk at generere naturlige sprogtekster og opfylde forskellige kommunikative brugerkrav såsom at skrive artikler, sange eller endda chatte med brugerne.
Maskinoversættelse
LLM'er kan også bruges til at oversætte tekst mellem to forskellige sprog. Modellerne udnytter dybe læringsalgoritmer, såsom tilbagevendende neurale netværk, til at lære sprogstrukturen af kilde- og målsprogene. Derfor bruges de til at oversætte kildetekst til målsproget.
Content Creation
LLM'er har nu gjort det muligt for maskiner at skabe sammenhængende og logisk indhold, der kan bruges til at generere blogindlæg, artikler og andre former for indhold. Modellerne bruger deres omfattende dybdegående viden til at forstå og strukturere indholdet i et unikt og læsbart format for brugerne.
Følelsesanalyse
Det er en spændende anvendelse af store sprogmodeller, hvor modellen er trænet til at identificere og klassificere følelsesmæssige tilstande og følelser i mærket tekst. Softwaren kan registrere følelser som positivitet, negativitet, neutralitet og andre komplekse følelser, der kan hjælpe med at få indsigt i kundernes meninger og anmeldelser om forskellige produkter og tjenester.
Forståelse, opsummering og klassificering af tekst
LLM'er giver en praktisk ramme for AI-softwaren til at forstå teksten og dens kontekst. Ved at træne modellen til at forstå og analysere store dynger af data, gør LLM det muligt for AI-modeller at forstå, opsummere og endda klassificere tekst i forskellige former og mønstre.
Besvarelse af spørgsmål
Store sprogmodeller gør det muligt for QA-systemer nøjagtigt at detektere og svare på en brugers naturlige sprogforespørgsel. En af de mest populære anvendelser af denne use case er ChatGPT og BERT, som analyserer konteksten af en forespørgsel og søger gennem et stort korpus af tekster for at finde relevante svar på brugerforespørgsler.
[Læs også: Fremtiden for sprogbehandling: Store sprogmodeller og eksempler ]

3 væsentlige betingelser for at få LLM'er til at lykkes
Følgende tre betingelser skal være nøjagtigt opfyldt for at øge effektiviteten og gøre dine store sprogmodeller succesfulde:
Tilstedeværelse af enorme mængder data til modeltræning
LLM har brug for store mængder data for at træne modeller, der giver effektive og optimale resultater. Der er specifikke metoder, såsom overførselslæring og selvovervåget fortræning, som LLM'erne udnytter til at forbedre deres ydeevne og nøjagtighed.
Opbygning af lag af neuroner for at lette komplekse mønstre til modellerne
En stor sprogmodel skal omfatte forskellige lag af neuroner, der er specielt trænet til at forstå de indviklede mønstre i data. Neuroner i dybere lag kan bedre forstå komplekse mønstre end lavere lag. Modellen kan lære sammenhængen mellem ord, de emner, der optræder sammen, og forholdet mellem dele af tale.
Optimering af LLM'er til brugerspecifikke opgaver
LLM'er kan tilpasses til specifikke opgaver ved at ændre antallet af lag, neuroner og aktiveringsfunktioner. For eksempel bruger en model, der forudsiger det følgende ord i sætningen, normalt færre lag og neuroner end en model designet til at generere nye sætninger fra bunden.
Populære eksempler på store sprogmodeller
Her er et par fremtrædende eksempler på LLM'er, der anvendes bredt i forskellige brancher:
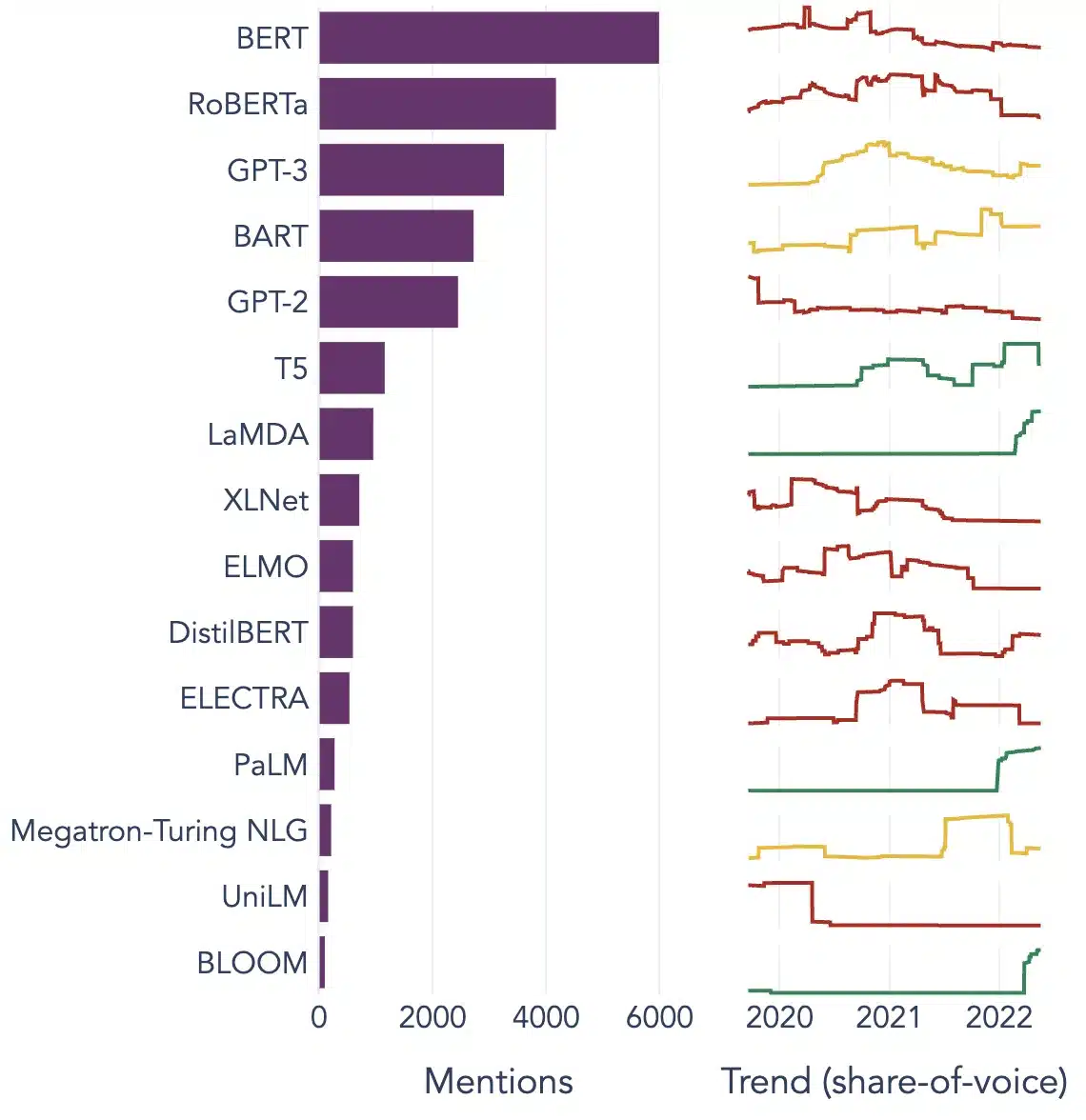
Billede Kilde: Mod datavidenskab
Konklusion
LLM'er ser potentialet til at revolutionere NLP ved at levere robuste og nøjagtige sprogforståelsesmuligheder og løsninger, der leverer en problemfri brugeroplevelse. Men for at gøre LLM'er mere effektive skal udviklere udnytte højkvalitets taledata til at generere mere nøjagtige resultater og producere meget effektive AI-modeller.
Shaip er en af de førende AI-teknologiske løsninger, der tilbyder en bred vifte af taledata på over 50 sprog og flere formater. Lær mere om LLM og få vejledning om dine projekter fra Shaip-eksperter i dag.