
Internettet har åbnet dørene for, at folk frit kan udtrykke deres meninger, synspunkter og forslag om stort set alt i verden på sociale medier, hjemmesider og blogs. Udover at give udtryk for deres meninger, påvirker folk (kunder) også andres købsbeslutninger. Stemningen, uanset om den er negativ eller positiv, er kritisk for enhver virksomhed eller brand, der er bekymret for salget af deres produkter eller tjenester.
At hjælpe virksomheder med at udvinde kommentarerne til forretningsbrug er Natural Language Processing. Hver fjerde virksomhed har planer om at implementere NLP-teknologi inden for det næste år for at styre deres forretningsbeslutninger. Ved hjælp af sentimentanalyse hjælper NLP virksomheder med at udlede fortolkelig indsigt fra rå og ustrukturerede data.
Mening minedrift eller følelser analyse er en NLP-teknik, der bruges til at identificere den nøjagtige følelse - positiv, negativ eller neutral – forbundet med kommentarer og feedback. Ved hjælp af NLP analyseres nøgleord i kommentarerne for at bestemme de positive eller negative ord, der er indeholdt i søgeordet.
Følelser bedømmes på et skaleringssystem, der tildeler stemningsscore til følelser i et stykke tekst (bestemmer teksten som positiv eller negativ).
Hvad er flersproget følelsesanalyse?

Som navnet antyder, flersproget følelsesanalyse er teknikken til at udføre sentiment score for mere end ét sprog. Det er dog ikke så enkelt som det. Vores kultur, sprog og oplevelser har stor indflydelse på vores købsadfærd og følelser. Uden en god forståelse af brugerens sprog, kontekst og kultur er det umuligt præcist at forstå brugerens intentioner, følelser og fortolkninger.
Selvom automatisering er svaret på mange af vores moderne problemer, maskine oversættelse software vil ikke være i stand til at opfange sprogets nuancer, talemåder, subtiliteter og kulturelle referencer i kommentarerne og anmeldelser det oversætter. ML-værktøjet giver dig muligvis en oversættelse, men det er måske ikke nyttigt. Det er grunden til, at flersproget følelsesanalyse er påkrævet.
Hvorfor er der behov for flersproget sentimentanalyse?
De fleste virksomheder bruger engelsk som deres kommunikationsmedie, men det bruges ikke af de fleste forbrugere verden over.
Ifølge Ethnologue taler omkring 13 % af verdens befolkning engelsk. Derudover siger British Council, at omkring 25% af verdens befolkning har en anstændig forståelse af engelsk. Hvis man skal tro disse tal, så interagerer en stor del af forbrugerne med hinanden og virksomheden på et andet sprog end engelsk.
Hvis hovedformålet med virksomheder er at holde deres kundebase intakt og tiltrække nye kunder, skal den indgående forstå deres kunders meninger udtrykt i deres modersmål. Manuel gennemgang af hver kommentar eller oversættelse af dem til engelsk er en besværlig proces, som ikke vil give effektive resultater.
En bæredygtig løsning er at udvikle flersproget sentiment analyse systemer der registrerer og analyserer kundernes meninger, følelser og forslag i sociale medier, fora, undersøgelser og mere.
Trin til at udføre flersproget sentimentanalyse
Følelsesanalyse, uanset om det er på et enkelt sprog eller Flere sprog, er en proces, der kræver anvendelse af maskinlæringsmodeller, naturlig sprogbehandling og dataanalyseteknikker for at udtrække flersproget følelsesscoring fra dataene.
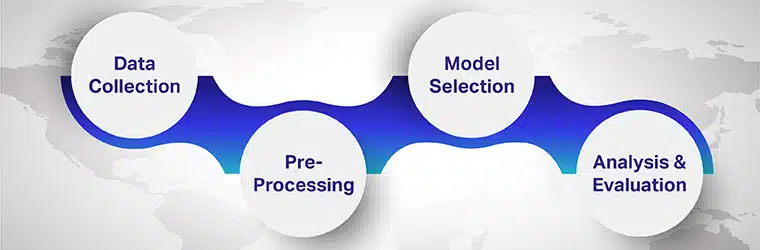
De trin, der er involveret i flersproget følelsesanalyse, er
Trin 1: Indsamling af data
Indsamling af data er det første skridt i at anvende sentimentanalyse. At skabe en flersproget stemningsanalysemodel, er det vigtigt at erhverve data på en række forskellige sprog. Alt vil afhænge af kvaliteten af data indsamlet, kommenteret og mærket. Du kan trække data fra API'er, open source-lagre og udgivere.
Trin 2: Forbehandling
De indsamlede webdata skal renses, og der skal hentes information fra dem. De dele af teksten, der ikke giver nogen særlig betydning, såsom 'det' 'er' og mere, bør fjernes. Ydermere bør teksten grupperes i ordgrupper for at blive kategoriseret for at formidle en positiv eller negativ betydning.
For at forbedre klassificeringskvaliteten bør indholdet renses for støj, såsom HTML-tags, reklamer og scripts. Sprog, leksikon og grammatik, der bruges af mennesker, er forskellige afhængigt af det sociale netværk. Det er vigtigt at normalisere sådant indhold og forberede det til forbehandling.
Et andet kritisk trin i forbehandling er at bruge naturlig sprogbehandling til at opdele sætninger, fjerne stopord, mærke dele af tale, transformere ord til deres rodform og tokenisere ord til symboler og tekst.
Trin 3: Modelvalg
Regelbaseret model: Den enkleste metode til flersproget semantisk analyse er regelbaseret. Den regelbaserede algoritme udfører analysen baseret på et sæt forudbestemte regler programmeret af eksperterne.
Reglen kan angive ord eller sætninger, der er positive eller negative. Hvis du f.eks. tager en anmeldelse af et produkt eller en tjeneste, kan den indeholde positive eller negative ord som "godt", "langsomt", "vent" og "nyttigt". Denne metode gør det nemt at klassificere ord, men den kan fejlklassificere komplicerede eller mindre hyppige ord.
Automatisk model: Den automatiske model udfører flersproget sentimentanalyse uden involvering af menneskelige moderatorer. Selvom maskinlæringsmodellen er bygget ved hjælp af menneskelig indsats, kan den arbejde automatisk for at levere præcise resultater, når den først er udviklet.
Testdata analyseres, og hver kommentar mærkes manuelt som positiv eller negativ. ML-modellen vil derefter lære af testdataene ved at sammenligne den nye tekst med de eksisterende kommentarer og kategorisere dem.
Trin 4: Analyse og evaluering
De regelbaserede og maskinlæringsmodeller kan forbedres og forbedres over tid og erfaring. Et leksikon med mindre hyppigt brugte ord eller livescore for flersprogede følelser kan opdateres for hurtigere og mere præcis klassificering.
Oversættelsens udfordring
Er oversættelse ikke nok? Faktisk nej!
Oversættelse involverer at overføre tekst eller grupper af tekst fra et sprog og finde en ækvivalent på et andet. Men oversættelse er hverken enkel eller effektiv.
Det er fordi mennesker bruger sproget ikke kun til at kommunikere deres behov, men også til at udtrykke deres følelser. Desuden er der markante forskelle mellem forskellige sprog, såsom engelsk, hindi, mandarin og thai. Tilføj til denne litterære blanding brugen af følelser, slang, idiomer, sarkasme og emojis. Det er ikke muligt at få en præcis oversættelse af teksten.
Nogle af de største udfordringer ved maskine oversættelse er
- subjektivitet
- Kontekst
- Slang og idiomer
- Sarcasm
- Sammenligninger
- neutralitet
- Emojis og moderne brug af ord.
Uden nøjagtigt at forstå den tilsigtede betydning af anmeldelser, kommentarer og kommunikation vedrørende deres produkter, priser, tjenester, funktioner og kvalitet, vil virksomheder ikke være i stand til at forstå kundernes behov og meninger.
Flersproget følelsesanalyse er en udfordrende proces. Hvert sprog har sit unikke leksikon, syntaks, morfologi og fonologi. Læg hertil kulturen, slangen, følelser udtrykt, sarkasme og tonalitet, og du har et udfordrende puslespil, der kræver en effektiv AI-drevet ML-løsning.
Et omfattende flersproget datasæt er nødvendigt for at udvikle robust flersproget værktøjer til følelsesanalyse der kan behandle anmeldelser og give stærk indsigt til virksomheder. Shaip er markedsleder i at levere branchetilpassede, mærkede, kommenterede datasæt på flere sprog, der hjælper med at udvikle effektive og nøjagtige flersprogede løsninger til sentimentanalyse.


