
Nøglen til at overvinde AI-udviklingshindringer: mere pålidelige data
I dag har den gennemsnitlige person nu millioner af gange mere computerkraft i lommen, end NASA måtte trække månelandingen ud i 1969. Den samme allestedsnærværende enhed, der bekvemt viser en overflod af computerkraft, opfylder også en anden forudsætning for AIs guldalder: en overflod af data. Ifølge indsigter fra Information Overload Research Group blev 90% af verdens data oprettet i de sidste to år. Nu hvor den eksponentielle vækst i computerkraft endelig er konvergeret med lige så meteorisk vækst i genereringen af data, eksploderer AI-datainnovationer så meget, at nogle eksperter tror, at de vil starte en fjerde industrielle revolution.
Data fra National Venture Capital Association indikerer, at AI-sektoren oplevede en rekordinvestering på 6.9 milliarder dollars i første kvartal af 2020. Det er ikke svært at se potentialet i AI-værktøjer, fordi det allerede bliver tappet rundt omkring os. Nogle af de mere synlige brugssituationer til AI-produkter er anbefalingsmotorer bag vores yndlingsapplikationer som Spotify og Netflix. Selvom det er sjovt at opdage en ny kunstner at lytte til eller et nyt tv-show at binge-watch, er disse implementeringer ret lave. Andre algoritmer vurderer testresultater - dels bestemmer, hvor studerende accepteres på college - og stadig andre skifter gennem kandidatresuméer og beslutter, hvilke ansøgere der får et bestemt job. Nogle AI-værktøjer kan endda have liv-eller-død-implikationer, såsom AI-modellen, der screener for brystkræft (som overgår læger).
På trods af stabil vækst i både virkelige eksempler på AI-udvikling og antallet af startups, der kæmper for at skabe den næste generation af transformationsværktøjer, er der stadig udfordringer med hensyn til effektiv udvikling og implementering. Især er AI-output kun så nøjagtigt som input tillader, hvilket betyder, at kvalitet er altafgørende.

Navigering af komplekse krav til overholdelse
Som om at finde kvalitetsdata ikke var svært nok, er nogle af de industrier, der står for at få mest ud af AI-datainnovationer, også de mest regulerede. Sundhedspleje er måske det bedste eksempel, og mens en undersøgelse fra HIT Infrastructure viste, at 91% af industriens insidere mener, at teknologien kunne forbedre adgangen til pleje, er optimismen tempereret af det faktum, at 75% ser det som en trussel mod patientsikkerhed og privatlivets fred. - og patienter er ikke de eneste i fare.
De omfattende regler vedtaget gennem Health Insurance Portability and Accountability Act skærer nu hinanden med forskellige lokale dataoverholdelseshindringer, såsom Europas generelle databeskyttelsesforordning, California Consumer Privacy Act i USA og persondatabeskyttelsesloven i Singapore. Disse lokale regler vil blive tilsluttet af mange flere, og da telesundhed fremstår som en mere vigtig kilde til sundhedsdata, er det sandsynligt, at regler vil få et endnu strammere greb om patientdata under transit. Som et resultat vil Shaips sikre og kompatible cloudplatform vise sig at være et endnu mere værdifuldt middel til at samle og få adgang til sundhedsdata for at træne AI-produkter.
Personligt identificerbare oplysninger kan være en væsentlig trussel mod din AI-udvikling, men endda en fuldstændig implementering er i fare, hvis den ikke kan levere den slags nøjagtige resultater, der kun kommer med forskellige træningsdata. En 2020-undersøgelse i Journal of the American Medical Association viste, at maskinindlæringsalgoritmer inden for det medicinske område oftest trænes med data fra patienter i Californien, New York og Massachusetts. I betragtning af at disse patienter repræsenterer mindre end en femtedel af den amerikanske befolkning, for ikke at sige noget om resten af verden, er det svært at forestille sig, hvordan disse modeller kunne producere andet end partiske resultater.

 Shaip anerkender vanskelighederne med at sikre kompatible, geografisk forskelligartede oplysninger og tilbyder licenserede sundhedsdata fra en lang række regioner, der er specifikt kurateret med det formål at konstruere nøjagtige algoritmer. Disse data kommer i form af tekst, såsom medicinske optegnelser eller kravoplysninger, medicinsk diagnostisk billeddannelse som CT-scanninger, lyd såsom talte noter fra læger eller samtaler mellem læger og patienter og endda video fra MR-resultater. Det er også fuldstændigt deidentificeret og anonymiseret og beskytter din organisation mod både de etiske og økonomiske konsekvenser, der kan følge en overtrædelse af ethvert af det stigende antal regler, der styrer data af både indenlandsk og international oprindelse.
Shaip anerkender vanskelighederne med at sikre kompatible, geografisk forskelligartede oplysninger og tilbyder licenserede sundhedsdata fra en lang række regioner, der er specifikt kurateret med det formål at konstruere nøjagtige algoritmer. Disse data kommer i form af tekst, såsom medicinske optegnelser eller kravoplysninger, medicinsk diagnostisk billeddannelse som CT-scanninger, lyd såsom talte noter fra læger eller samtaler mellem læger og patienter og endda video fra MR-resultater. Det er også fuldstændigt deidentificeret og anonymiseret og beskytter din organisation mod både de etiske og økonomiske konsekvenser, der kan følge en overtrædelse af ethvert af det stigende antal regler, der styrer data af både indenlandsk og international oprindelse.
Overvinde AI-udviklingshindringer
AI-udviklingsindsats inkluderer betydelige hindringer, uanset hvilken industri de finder sted i, og processen med at komme fra en mulig idé til et vellykket produkt er fyldt med vanskeligheder. Mellem udfordringerne ved at erhverve de rigtige data og behovet for at anonymisere dem for at overholde alle relevante regler, kan det føles som at konstruere og træne en algoritme er den nemme del.
For at give din organisation alle fordele, der er nødvendige i bestræbelserne på at designe en banebrydende ny AI-udvikling, vil du overveje at samarbejde med et firma som Shaip. Chetan Parikh og Vatsal Ghiya grundlagde Shaip for at hjælpe virksomheder med at konstruere de slags løsninger, der kunne omdanne sundhedsydelser i USA. Efter mere end 16 år i erhvervslivet er vores firma vokset til at omfatte mere end 600 teammedlemmer, og vi har arbejdet med hundreder af kunder til at gøre overbevisende ideer til AI-løsninger.
Med vores medarbejdere, processer og platform, der arbejder for din organisation, kan du straks låse op for følgende fire fordele og katapultere dit projekt mod en vellykket afslutning:
1. Evnen til at befri dine dataforskere
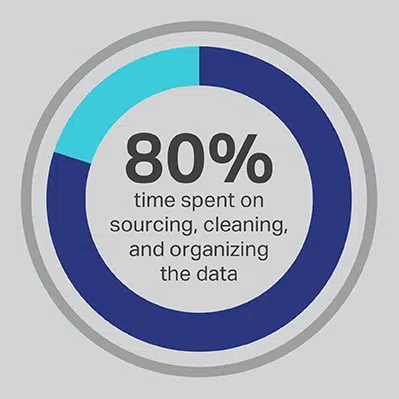
Det er ikke til at komme uden om, at AI -udviklingsprocessen tager en betydelig investering af tid, men du kan altid optimere de funktioner, dit team bruger mest tid på at udføre. Du hyrede dine dataforskere, fordi de er eksperter i udviklingen af avancerede algoritmer og maskinlæringsmodeller, men forskningen viser konsekvent, at disse medarbejdere faktisk bruger 80% af deres tid på at skaffe, rense og organisere de data, der driver projektet. Mere end tre fjerdedele (76%) af dataforskere rapporterer, at disse verdslige dataindsamlingsprocesser også tilfældigvis er deres mindst foretrukne dele af jobbet, men behovet for kvalitetsdata efterlader kun 20% af deres tid til egentlig udvikling, hvilket er det mest interessante og intellektuelt stimulerende arbejde for mange dataforskere. Ved at skaffe data via en tredjepartsleverandør som Shaip, kan en virksomhed lade sine dyre og talentfulde dataingeniører outsource deres arbejde som datevagter og i stedet bruge deres tid på dele af AI-løsninger, hvor de kan producere mest værdi.
2. Evnen til at opnå bedre resultater
 Mange AI-udviklingsledere beslutter at bruge open source eller crowdsourced data for at reducere udgifter, men denne beslutning ender næsten altid med at koste mere i det lange løb. Disse typer data er let tilgængelige, men de kan ikke matche kvaliteten af omhyggeligt kuraterede datasæt. Især Crowdsourced-data er rig på fejl, udeladelser og unøjagtigheder, og selvom disse problemer undertiden kan sorteres under udviklingsprocessen under dine ingeniørers opmærksomme øjne, tager det yderligere iterationer, der ikke ville være nødvendige, hvis du startede med højere -kvalitetsdata fra starten.
Mange AI-udviklingsledere beslutter at bruge open source eller crowdsourced data for at reducere udgifter, men denne beslutning ender næsten altid med at koste mere i det lange løb. Disse typer data er let tilgængelige, men de kan ikke matche kvaliteten af omhyggeligt kuraterede datasæt. Især Crowdsourced-data er rig på fejl, udeladelser og unøjagtigheder, og selvom disse problemer undertiden kan sorteres under udviklingsprocessen under dine ingeniørers opmærksomme øjne, tager det yderligere iterationer, der ikke ville være nødvendige, hvis du startede med højere -kvalitetsdata fra starten.
At stole på open source-data er en anden almindelig genvej, der kommer med sit eget sæt faldgruber. Manglende differentiering er et af de største problemer, fordi en algoritme, der trænes ved hjælp af open source-data, lettere replikeres end en, der er bygget på licenserede datasæt. Ved at gå denne rute inviterer du konkurrence fra andre deltagere i rummet, der til enhver tid kan underbære dine priser og tage markedsandele. Når du stoler på Shaip, får du adgang til de højeste kvalitetsdata samlet af en dygtig administreret arbejdsstyrke, og vi kan give dig en eksklusiv licens til et brugerdefineret datasæt, der forhindrer konkurrenter i let at genskabe din hårdt vundne intellektuelle ejendom.
3. Adgang til erfarne fagfolk
 Selvom din interne liste inkluderer dygtige ingeniører og talentfulde dataforskere, kan dine AI-værktøjer drage fordel af den visdom, der kun kommer gennem erfaring. Vores emneeksperter har stået i spidsen for adskillige AI-implementeringer inden for deres områder og lært værdifulde lektioner undervejs, og deres eneste mål er at hjælpe dig med at opnå din.
Selvom din interne liste inkluderer dygtige ingeniører og talentfulde dataforskere, kan dine AI-værktøjer drage fordel af den visdom, der kun kommer gennem erfaring. Vores emneeksperter har stået i spidsen for adskillige AI-implementeringer inden for deres områder og lært værdifulde lektioner undervejs, og deres eneste mål er at hjælpe dig med at opnå din.
Med domæneeksperter, der identificerer, organiserer, kategoriserer og mærker data til dig, ved du, at de oplysninger, der bruges til at træne din algoritme, kan give de bedst mulige resultater. Vi udfører også regelmæssig kvalitetssikring for at sikre, at data lever op til de højeste standarder og vil fungere som tilsigtet ikke kun i et laboratorium, men også i en reel situation.
4. En accelereret tidslinje for udvikling
AI-udvikling sker ikke natten over, men det kan ske hurtigere, når du samarbejder med Shaip. Intern dataindsamling og -notering skaber en betydelig operationel flaskehals, der holder resten af udviklingsprocessen. Arbejdet med Shaip giver dig øjeblikkelig adgang til vores enorme bibliotek med brugsklare data, og vores eksperter er i stand til at hente enhver form for yderligere input, du har brug for, med vores dybe brancheviden og globale netværk. Uden byrden ved sourcing og annotering kan dit team straks komme i gang med den faktiske udvikling, og vores træningsmodel kan hjælpe med at identificere tidlige unøjagtigheder for at reducere de iterationer, der er nødvendige for at nå nøjagtighedsmålene.
Hvis du ikke er klar til at outsource alle aspekter af din datastyring, tilbyder Shaip også en skybaseret platform, der hjælper teams med at producere, ændre og kommentere forskellige typer data mere effektivt, herunder support til billeder, video, tekst og lyd . ShaipCloud inkluderer en række intuitive værktøjer til validering og workflow, såsom en patenteret løsning til at spore og overvåge arbejdsbelastninger, et transkriptionsværktøj til transskription af komplekse og vanskelige lydoptagelser og en kvalitetskontrolkomponent for at sikre kompromisløs kvalitet. Bedst af alt er det skalerbart, så det kan vokse, efterhånden som de forskellige krav til dit projekt øges.
Alderen for AI-innovation er kun lige begyndt, og vi vil se utrolige fremskridt og innovationer i de kommende år, der har potentialet til at omforme hele industrier eller endda ændre samfundet som helhed. Hos Shaip ønsker vi at bruge vores ekspertise til at fungere som en transformerende kraft, der hjælper de mest revolutionerende virksomheder i verden med at udnytte kraften i AI-løsninger til at nå ambitiøse mål.
Vi har stor erfaring inden for sundhedsapplikationer og AI, men vi har også de nødvendige færdigheder til at træne modeller til næsten enhver form for anvendelse. For mere information om, hvordan Shaip kan hjælpe med at tage dit projekt fra idé til implementering, se på de mange ressourcer, der er tilgængelige på vores hjemmeside eller nå ud til os i dag.
