
Har du nogensinde undret dig over, hvordan chatbots og virtuelle assistenter vågner op, når du siger 'Hej Siri' eller 'Alexa'? Det er på grund af tekstindsamlingen eller udløser ord indlejret i softwaren, der aktiverer systemet, så snart det hører det programmerede vækkeord.
Den overordnede proces med at skabe lyde og ytringsdata er dog ikke så enkel. Det er en proces, der skal udføres med den rigtige teknik for at få de ønskede resultater. Derfor vil denne blog dele ruten til at skabe gode ytringer/triggerord, der fungerer problemfrit med din samtale-AI.
Hvad er ytringer?
Ytringer kan omtales som sætninger eller triggerord, der bruges til at aktivere en kunstigt intelligent model. Når din AI-model registrerer sit vågne ord, begynder den automatisk at optage brugerens næste anmodning og svarer med en passende handling eller svar.
Ytring bruger begrebet dyb læring til at lære softwaren, hvordan man genkender vågne ord. Når wake word aktiverer softwaren, begynder systemet at fange, afkode og servicere anmodningen. Når det ikke er i brug, bliver systemet passivt ved med at lytte efter triggerord.
For at din AI-software kan opnå nøjagtige resultater, er det vigtigt at fange et væld af forskellige ytringer for enhver hensigt. Det hjælper med bedre træning til AI-modellen.
[Læs også: Kunne du tænke dig at vide, hvordan Siri og Alexa forstår dig?]
Punkter at huske, mens du opretter et lager af ytringer
Nu hvor vi ved, at træning er vigtigt for AI-modeller, er den næste ting at vide, hvordan man giver ytringer til AI-modellerne. Normalt oprettes et lager af ytringer for at træne samtale-AI'er.
Der er dog forskellige ting, man skal huske, når man bygger arkiver af ytringer. Følgende er de ting, du skal overveje:
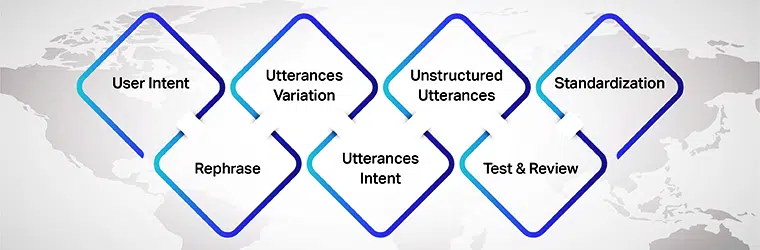
Brugerhensigt
Først og fremmest, mens du forbereder ytringer til din AI-model, skal du sikre dig, at du forstår brugerhensigten, som du udvikler datasættene til. Du skal finde ud af de forskellige ytringer, som brugere kan indtaste, mens de taler med AI-modellen.
Variation af ytringer
Variationer er en væsentlig del af denne proces, da jo flere variationer for hver hensigt, jo bedre resultater vil du opnå. Så sørg for at oprette flere variationer af brugerytringer. Du kan gøre det ved
- Oprettelse af korte, mellemstore og store sætninger til de samme sætninger.
- Ændring af ord og længde på sætninger.
- Brug unikke ord.
- Pluralisering af sætningerne.
- At blande grammatikken.



