



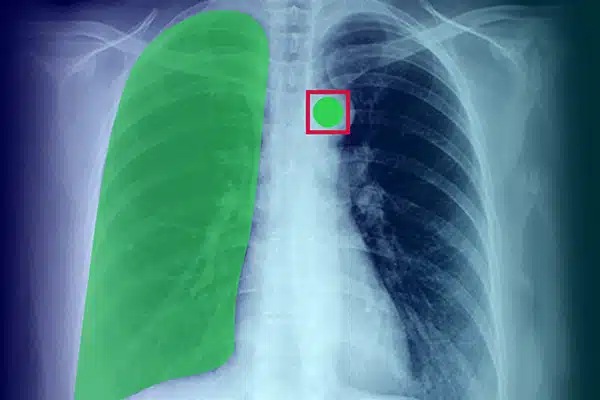
Billedannotation
Forbedre medicinsk AI ved at annotere visuelle data fra røntgenbilleder, CT-scanninger og MR'er. Sørg for, at AI-modeller yder fremragende i diagnostik og behandling, styret af ekspertdatamærkning. Få bedre patientresultater med overlegen billedbehandlingsindsigt.
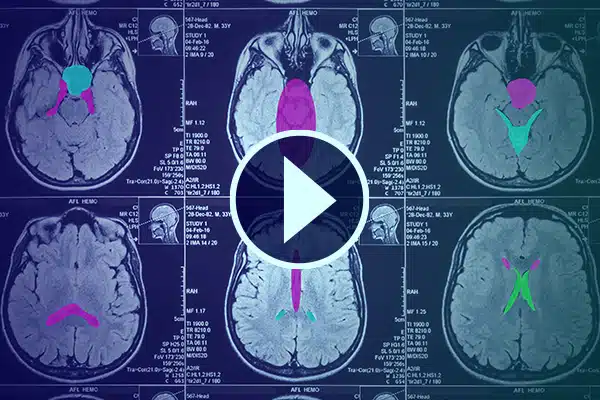
Video-kommentar
Avancer AI i sundhedsvæsenet med detaljerede videoannoteringer. Skærp AI-læring med klassifikationer og segmenteringer i medicinske optagelser. Forbedre din kirurgiske AI og patientovervågning for forbedret levering af sundhedsydelser og diagnostik.
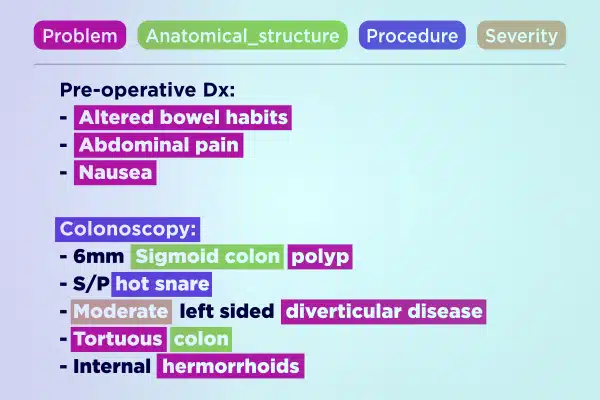
Tekstkommentar
Strømlin medicinsk AI-udvikling med ekspertkommenterede tekstdata. Parse og berig hurtigt store tekstmængder, fra håndskrevne noter til forsikringsrapporter. Sikre præcise og handlingsrettede indsigter for sundhedsfremskridt.

Lydkommentar
Udnyt NLP-ekspertise til at kommentere og mærke medicinske lyddata nøjagtigt. Lav stemmeassisterede systemer til problemfri klinisk drift, og integrer AI i forskellige stemmeaktiverede sundhedsprodukter. Forbedre diagnostisk præcision med ekspert lyddatakuration.

Medicinsk kodning
Strømlin medicinsk dokumentation ved at konvertere den til universelle koder med AI medicinsk kodning. Sikre nøjagtighed, forbedre faktureringseffektiviteten og understøtte problemfri levering af sundhedsydelser med banebrydende AI-assistance i medicinsk journalkodning.

Fase 1: Teknisk domæneekspertise (forstå retningslinjer for omfang og annoteringer)

Fase 2: Uddannelse af passende ressourcer til projektet

Fase 3: Feedback cyklus og QA af de kommenterede dokumenter
Radiologi
Vores radiologibilledannoteringstjeneste skærper AI-diagnostik og inkluderer et ekstra lag af ekspertise. Hver røntgen-, MR- og CT-scanning er omhyggeligt mærket og gennemgået af en fagekspert. Dette ekstra trin i træning og gennemgang booster AI'ens evne til at opdage abnormiteter og sygdomme. Det øger nøjagtigheden før levering til vores kunder.

Kardiologi
Vores kardiologi-fokuserede billedannotering skærper AI-diagnostik. Vi henter kardiologiske eksperter, som mærker komplekse hjerterelaterede billeder og træner vores AI-modeller. Inden vi sender data til kunder, gennemgår disse specialister hvert billede for at sikre den højeste nøjagtighed. Denne proces gør AI i stand til at opdage hjertesygdomme mere præcist.
Tandpleje
Vores billedannoteringstjeneste i tandplejen mærker tandbilleder for at forbedre AI-diagnoseværktøjer. Ved nøjagtigt at identificere huller i tænderne, problemer med justering og andre tandtilstande giver vores SMV'er AI i stand til at forbedre patientresultater og støtte tandlæger i præcis behandlingsplanlægning og tidlig opdagelse.


















Mennesker
Dedikerede og uddannede hold:
- 30,000+ samarbejdspartnere til oprettelse af data, mærkning og kvalitetssikring
- Godkendt projektledelsesteam
- Erfaren produktudviklingsteam
- Talent Pool Sourcing & Onboarding Team

Proces
Højeste proceseffektivitet sikres med:
- Robust 6 Sigma Stage-Gate-proces
- Et dedikeret team med 6 Sigma-sorte bælter - Nøgleprocessejere og overholdelse af kvalitet
- Løbende forbedring og feedback

perron
Den patenterede platform giver fordele:
- Web-baseret ende-til-ende platform
- Upåklagelig kvalitet
- Hurtigere TAT
- Problemfri levering



