


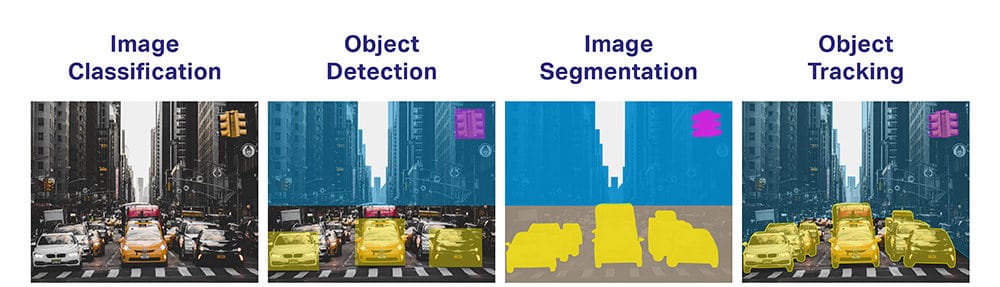
- Objektklassificering: Hvilken bred kategori af objekter er der?
- Objektidentifikation: Hvilken type af et givet objekt er der?
- Objektbekræftelse: Hvilket er objektet på fotografiet?
- Objektregistrering: Hvor er genstandene på fotografiet?
- Objektdetektion af vartegn: Hvad er nøglepunkterne for objektet på fotografiet?
- Objektsegmentering: Hvilke pixels hører til objektet i billedet?
- Objektgenkendelse: Hvilke objekter er der på dette fotografi, og hvor er de?

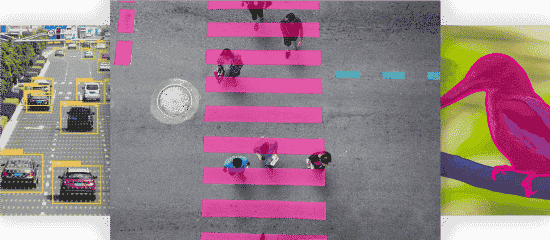


Billedsamling

Video Collection

Afgrænsningskasser

3D Cuboids
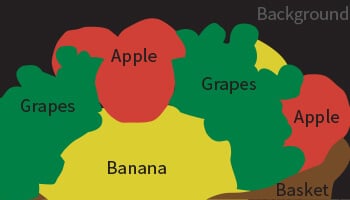
Semantisk segmentering

Kommentar til polygon

Vartegn-kommentar

Linjesegmentering

Billedtranskription
Video Transcription

Billedklassificering
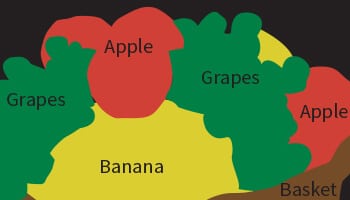
Billedsegmentering

Kommentar om billedtastatur

Videoklassificering
Videosegmentering

- Brug Case: ADAS-model i bilen
- Format: Billeder
- Volumen: 455,000 +
- Kommentar: Ingen

- Brug Case: Landmark Detection
- Format: Billeder
- Volumen: 80,000 +
- Kommentar: Ingen

- Brug Case: Spor af fodgængere
- Format: Videoer
- Volumen: 84,500 +
- Kommentar: Ja

- Brug Case: Fødevaregenkendelse
- Format: Billeder
- Volumen: 55,000 +
- Kommentar: Ja

Sundhedspleje AI
Træn ML-modeller til at opdage kræftflekker i hudbilleder eller finde symptomer ved MR-scanninger eller patientens røntgen.

ansigtsgenkendelse
Træn ML-modeller til at identificere billeder af mennesker baseret på ansigtsegenskaber og sammenligne dem med en database med ansigtsprofiler for at opdage og mærke mennesker.

Geospatiale applikationer
Annotering af satellitbilleder og UAV -fotografering for at forberede datasæt til geoprocessering og annotere 3D -punktsky for Geo.AI.

Augmented Reality
Placer virtuelle objekter i den virkelige verden med AR-headset. Det kan registrere plane overflader som vægge, bordplader og gulve - en meget kritisk del i etablering af dybde og dimensioner og placering af virtuelle objekter i den fysiske verden.

Selvkørende biler
Flere kameraer optager videoer fra en anden vinkel for at identificere grænserne for trafiksignaler, veje, biler, genstande og fodgængere i nærheden for at træne selvkørende biler til automatisk at styre køretøjet og undgå at ramme forhindringer, mens de kører passageren sikkert.

Detail / e-handel
Med edb -vision i detailhandelen kan applikationerne tilbyde personlige anbefalinger baseret på kunders købsmønstre og fremskynde forretningsdriften som hyldehåndtering, betalinger osv.




Mennesker
Dedikerede og uddannede hold:
- 30,000+ samarbejdspartnere til oprettelse af data, mærkning og kvalitetssikring
- Godkendt projektledelsesteam
- Erfaren produktudviklingsteam
- Talent Pool Sourcing & Onboarding Team

Proces
Højeste proceseffektivitet sikres med:
- Robust 6 Sigma Stage-Gate-proces
- Et dedikeret team med 6 Sigma-sorte bælter - Nøgleprocessejere og overholdelse af kvalitet
- Løbende forbedring og feedback

perron
Den patenterede platform giver fordele:
- Web-baseret ende-til-ende platform
- Upåklagelig kvalitet
- Hurtigere TAT
- Problemfri levering
Mennesker
Dedikerede og uddannede hold:
- 30,000+ samarbejdspartnere til oprettelse af data, mærkning og kvalitetssikring
- Godkendt projektledelsesteam
- Erfaren produktudviklingsteam
- Talent Pool Sourcing & Onboarding Team
Proces
Højeste proceseffektivitet sikres med:
- Robust 6 Sigma Stage-Gate-proces
- Et dedikeret team med 6 Sigma-sorte bælter - Nøgleprocessejere og overholdelse af kvalitet
- Løbende forbedring og feedback
perron
Den patenterede platform giver fordele:
- Web-baseret ende-til-ende platform
- Upåklagelig kvalitet
- Hurtigere TAT
- Problemfri levering