




Styrkelse af sundhedsvæsenet med generativ kunstig intelligens: Revolutionerende diagnose og behandling
I de senere år har kunstig intelligens (AI) gjort betydelige fremskridt i forskellige brancher, og sundhedsvæsenet er ingen undtagelse. Generativ AI, en undergruppe af AI-fokuseret
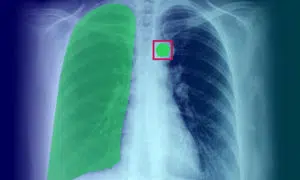
Medicinsk billedanmærkning: Definition, anvendelse, brugssager og typer
Medicinsk billedannotering spiller en afgørende rolle i at give maskinlæringsalgoritmer og AI-modeller de nødvendige træningsdata. Denne proces er afgørende for

Etik og bias: Navigering af udfordringerne ved menneske-AI-samarbejde i modelevaluering
I søgen efter at udnytte den transformative kraft af kunstig intelligens (AI), står teknologisamfundet over for en kritisk udfordring: at sikre etisk integritet og minimere bias

The Human Touch: Forbedring af AI-kreativitet med subjektiv evaluering
I den hastigt udviklende verden af kunstig intelligens (AI) er søgen efter kreativitet ikke længere kun en menneskelig bestræbelse. Nutidens AI-teknologier er ved at bryde

Maksimering af søgerelevans med datamærkning: Tips og bedste praksis
Brugere i dag er nedsænket i enorme mængder af information, hvilket gør det kompliceret at finde den information, de har brug for. Søgerelevans måler nøjagtigheden af information en

Bridging the Gap: Integrering af menneskelig intuition i AI-modelevaluering
Introduktion I en æra, hvor kunstig intelligens (AI) former alle facetter af vores liv, opstår integrationen af menneskelig intuition i AI-modelevaluering som

Bedste Open Source Healthcare-datasæt til maskinlæringsprojekter
Det globale sundhedssystem producerer dagligt enorme mængder medicinske data, som har potentiale til at blive brugt til maskinlæringsapplikationer.

Navigering af databeskyttelse i AI: Strategier for overholdelse og innovation
Introduktion I det hurtigt udviklende landskab af kunstig intelligens (AI) står virksomheder som OpenAI over for betydelige udfordringer med at balancere det umættelige behov for data med stringente
Fremtiden for data med Intelligent Character Recognition (ICR)
Håndskrevne noter har en særlig charme selv i vores digitale verden. Intelligent Character Recognition (ICR) hjælper med at bygge bro over den analoge og digitale kløft ved at konvertere håndskrevet tekst

Indvirkningen af NLP på sundhedsdiagnostik
Natural Language Processing (NLP) transformerer, hvordan vi interagerer med teknologi. Det behandler menneskeligt sprog for at frigøre et stort informationspotentiale. Teknologien rummer det samme potentiale

Valg af det rigtige talegenkendelsesdatasæt til din AI-model
Forestil dig at interagere med Siri eller Alexa. Deres evne til at forstå vores tale er fascinerende. Denne evne stammer fra de datasæt, der bruges i deres træning. Disse

Sundhedsdatasæt: Boon for Healthcare AI
Kunstig intelligens, et begreb, der engang fandtes mest i science fiction, er nu en realitet, der giver næring til væksten i forskellige industrier. Next Move Strategirådgivning

Forstærkende læring med menneskelig feedback: definition og trin
Reinforcement learning (RL) er en type maskinlæring. I denne tilgang lærer algoritmer at træffe beslutninger gennem forsøg og fejl, ligesom mennesker gør.

Årsager til AI-hallucinationer (og teknikker til at reducere dem)
AI-hallucinationer refererer til tilfælde, hvor AI-modeller, især store sprogmodeller (LLM'er), genererer information, der ser ud til at være sand, men som er forkert eller ikke er relateret til

Hvad er klinisk validering? Din guide til bedste praksis og processer
Tænk på et scenarie, hvor et nyt diagnostisk værktøj udvikles. Læger er begejstrede for dets potentiale. Men før de integrerer det i rutineplejen,

Vigtigheden af etisk AI / Fair AI og typer af skævheder, der skal undgås
I det spirende felt af kunstig intelligens (AI) er fokus på etiske overvejelser og retfærdighed mere end et moralsk imperativ – det er en grundlæggende nødvendighed for

Opsummering af AI Medical Records: Definition, udfordringer og bedste praksis
Væksten i lægejournaler i sundhedssektoren er blevet både en udfordring og en mulighed. Forestil dig en verden, hvor hver detalje i en

Klinisk dataabstraktion: definition, proces og mere
Hospitaler og klinikker støder på tusindvis af patienter hvert år. Dette kræver et stort antal dedikerede læger og sygeplejersker. De arbejder utrætteligt for at yde omsorg

Syntetiske data i sundhedsvæsenet: Definition, fordele og udfordringer
Forestil dig et scenarie, hvor forskere udvikler et nyt lægemiddel. De har brug for omfattende patientdata til test, men der er betydelige bekymringer om privatlivets fred og

HIPAA-ekspertbestemmelse for afidentifikation
Health Insurance Portability and Accountability Act (HIPAA) sætter standarden for beskyttelse af patientdata i sundhedsvæsenet. Et afgørende aspekt af dette er at afidentificere Protected

Banebrydende onkologisk forskning med NLP: Shaip-gennembruddet
Download Case Study I jagten på at erobre kræft er data lige så afgørende som beslutsomhed. Hos Shaip er vi stolte over at have muliggjort et stort spring
Kraften ved naturlig sprogbehandling (NLP) i radiologi: forbedring af diagnose og effektivitet
Radiologi spiller en afgørende rolle i sundhedsvæsenet. Det bruger billeddannelsesteknikker som CT-scanninger, røntgenstråler og MR til at diagnosticere og behandle forskellige tilstande. Naturligt sprog

Rollen af naturlig sprogbehandling (NLP) i onkologi
Kræft udgør en betydelig sundhedsudfordring globalt. Det sker, når celler vokser og spredes på en ukontrolleret måde. Det er den anden hyppigste dødsårsag

Alt hvad du behøver at vide om forstærkning at lære af menneskelig feedback
2023 oplevede en massiv stigning i adoptionen af AI-værktøjer som ChatGPT. Denne stigning satte gang i en livlig debat, og folk diskuterer AI's fordele,

Kraften af AI i bilindustrien
Når det kommer til at integrere kunstig intelligens i biler, står verden ved en bemærkelsesværdig skillevej. Forestil dig at køre på en befærdet vej med kunstig intelligens og styre din

Fordele ved tekst til tale på tværs af brancher
Tekst-til-tale (TTS) teknologi er en innovativ løsning, der konverterer skrevet tekst til talte ord. Det er blevet en game-changer i flere brancher og har revolutioneret

A til Z af dataanmærkninger
En begyndervejledning til dataanmærkning: Tips og bedste praksis The Ultimate Buyers Guide 2024 Indekstabel Introduktion Hvad er Machine Learning? Hvad er

Vejledning til afidentifikation af data: Alt, hvad en nybegynder behøver at vide (i 2024)
I en tid med digital transformation flytter sundhedsorganisationer hurtigt deres aktiviteter til digitale platforme. Selvom dette bringer effektivitet og strømlinede processer, er det også

Generativ kunstig intelligens i sundhedssektoren: applikationer, fordele, udfordringer og fremtidige tendenser
Sundhedspleje har altid været et område, hvor innovation er værdsat og afgørende for at redde liv. På trods af teknologiske fremskridt står sundhedsindustrien stadig over for vedvarende udfordringer.

Forskellen mellem ansvarlig AI og etisk AI
Det hurtigt voksende globale AI-marked forventes at nå op på 1847 milliarder dollars i 2030. Med AI i centrum i vores liv, ved at vide hvilken slags



















Styrkelse af sundhedsvæsenet med generativ kunstig intelligens: Revolutionerende diagnose og behandling
I de senere år har kunstig intelligens (AI) gjort betydelige fremskridt i forskellige brancher, og sundhedsvæsenet er ingen undtagelse. Generativ AI, en undergruppe af AI-fokuseret
Medicinsk billedanmærkning: Definition, anvendelse, brugssager og typer
Medicinsk billedannotering spiller en afgørende rolle i at give maskinlæringsalgoritmer og AI-modeller de nødvendige træningsdata. Denne proces er afgørende for
Etik og bias: Navigering af udfordringerne ved menneske-AI-samarbejde i modelevaluering
I søgen efter at udnytte den transformative kraft af kunstig intelligens (AI), står teknologisamfundet over for en kritisk udfordring: at sikre etisk integritet og minimere bias
The Human Touch: Forbedring af AI-kreativitet med subjektiv evaluering
I den hastigt udviklende verden af kunstig intelligens (AI) er søgen efter kreativitet ikke længere kun en menneskelig bestræbelse. Nutidens AI-teknologier er ved at bryde
Maksimering af søgerelevans med datamærkning: Tips og bedste praksis
Brugere i dag er nedsænket i enorme mængder af information, hvilket gør det kompliceret at finde den information, de har brug for. Søgerelevans måler nøjagtigheden af information en
Bridging the Gap: Integrering af menneskelig intuition i AI-modelevaluering
Introduktion I en æra, hvor kunstig intelligens (AI) former alle facetter af vores liv, opstår integrationen af menneskelig intuition i AI-modelevaluering som
Bedste Open Source Healthcare-datasæt til maskinlæringsprojekter
Det globale sundhedssystem producerer dagligt enorme mængder medicinske data, som har potentiale til at blive brugt til maskinlæringsapplikationer.
Navigering af databeskyttelse i AI: Strategier for overholdelse og innovation
Introduktion I det hurtigt udviklende landskab af kunstig intelligens (AI) står virksomheder som OpenAI over for betydelige udfordringer med at balancere det umættelige behov for data med stringente
Fremtiden for data med Intelligent Character Recognition (ICR)
Håndskrevne noter har en særlig charme selv i vores digitale verden. Intelligent Character Recognition (ICR) hjælper med at bygge bro over den analoge og digitale kløft ved at konvertere håndskrevet tekst
Indvirkningen af NLP på sundhedsdiagnostik
Natural Language Processing (NLP) transformerer, hvordan vi interagerer med teknologi. Det behandler menneskeligt sprog for at frigøre et stort informationspotentiale. Teknologien rummer det samme potentiale
Valg af det rigtige talegenkendelsesdatasæt til din AI-model
Forestil dig at interagere med Siri eller Alexa. Deres evne til at forstå vores tale er fascinerende. Denne evne stammer fra de datasæt, der bruges i deres træning. Disse
Sundhedsdatasæt: Boon for Healthcare AI
Kunstig intelligens, et begreb, der engang fandtes mest i science fiction, er nu en realitet, der giver næring til væksten i forskellige industrier. Next Move Strategirådgivning
Forstærkende læring med menneskelig feedback: definition og trin
Reinforcement learning (RL) er en type maskinlæring. I denne tilgang lærer algoritmer at træffe beslutninger gennem forsøg og fejl, ligesom mennesker gør.
Årsager til AI-hallucinationer (og teknikker til at reducere dem)
AI-hallucinationer refererer til tilfælde, hvor AI-modeller, især store sprogmodeller (LLM'er), genererer information, der ser ud til at være sand, men som er forkert eller ikke er relateret til
Hvad er klinisk validering? Din guide til bedste praksis og processer
Tænk på et scenarie, hvor et nyt diagnostisk værktøj udvikles. Læger er begejstrede for dets potentiale. Men før de integrerer det i rutineplejen,
Vigtigheden af etisk AI / Fair AI og typer af skævheder, der skal undgås
I det spirende felt af kunstig intelligens (AI) er fokus på etiske overvejelser og retfærdighed mere end et moralsk imperativ – det er en grundlæggende nødvendighed for
Opsummering af AI Medical Records: Definition, udfordringer og bedste praksis
Væksten i lægejournaler i sundhedssektoren er blevet både en udfordring og en mulighed. Forestil dig en verden, hvor hver detalje i en
Klinisk dataabstraktion: definition, proces og mere
Hospitaler og klinikker støder på tusindvis af patienter hvert år. Dette kræver et stort antal dedikerede læger og sygeplejersker. De arbejder utrætteligt for at yde omsorg
Syntetiske data i sundhedsvæsenet: Definition, fordele og udfordringer
Forestil dig et scenarie, hvor forskere udvikler et nyt lægemiddel. De har brug for omfattende patientdata til test, men der er betydelige bekymringer om privatlivets fred og
HIPAA-ekspertbestemmelse for afidentifikation
Health Insurance Portability and Accountability Act (HIPAA) sætter standarden for beskyttelse af patientdata i sundhedsvæsenet. Et afgørende aspekt af dette er at afidentificere Protected
Banebrydende onkologisk forskning med NLP: Shaip-gennembruddet
Download Case Study I jagten på at erobre kræft er data lige så afgørende som beslutsomhed. Hos Shaip er vi stolte over at have muliggjort et stort spring
Kraften ved naturlig sprogbehandling (NLP) i radiologi: forbedring af diagnose og effektivitet
Radiologi spiller en afgørende rolle i sundhedsvæsenet. Det bruger billeddannelsesteknikker som CT-scanninger, røntgenstråler og MR til at diagnosticere og behandle forskellige tilstande. Naturligt sprog
Rollen af naturlig sprogbehandling (NLP) i onkologi
Kræft udgør en betydelig sundhedsudfordring globalt. Det sker, når celler vokser og spredes på en ukontrolleret måde. Det er den anden hyppigste dødsårsag
Alt hvad du behøver at vide om forstærkning at lære af menneskelig feedback
2023 oplevede en massiv stigning i adoptionen af AI-værktøjer som ChatGPT. Denne stigning satte gang i en livlig debat, og folk diskuterer AI's fordele,
Kraften af AI i bilindustrien
Når det kommer til at integrere kunstig intelligens i biler, står verden ved en bemærkelsesværdig skillevej. Forestil dig at køre på en befærdet vej med kunstig intelligens og styre din
Fordele ved tekst til tale på tværs af brancher
Tekst-til-tale (TTS) teknologi er en innovativ løsning, der konverterer skrevet tekst til talte ord. Det er blevet en game-changer i flere brancher og har revolutioneret
A til Z af dataanmærkninger
En begyndervejledning til dataanmærkning: Tips og bedste praksis The Ultimate Buyers Guide 2024 Indekstabel Introduktion Hvad er Machine Learning? Hvad er
Vejledning til afidentifikation af data: Alt, hvad en nybegynder behøver at vide (i 2024)
I en tid med digital transformation flytter sundhedsorganisationer hurtigt deres aktiviteter til digitale platforme. Selvom dette bringer effektivitet og strømlinede processer, er det også
Generativ kunstig intelligens i sundhedssektoren: applikationer, fordele, udfordringer og fremtidige tendenser
Sundhedspleje har altid været et område, hvor innovation er værdsat og afgørende for at redde liv. På trods af teknologiske fremskridt står sundhedsindustrien stadig over for vedvarende udfordringer.
Forskellen mellem ansvarlig AI og etisk AI
Det hurtigt voksende globale AI-marked forventes at nå op på 1847 milliarder dollars i 2030. Med AI i centrum i vores liv, ved at vide hvilken slags

Hvad er NLP? Hvordan det virker, fordele, udfordringer, eksempler
Download infografik Hvad er NLP? Natural Language Processing (NLP) er et underområde af kunstig intelligens (AI). Det gør det muligt for robotter at analysere og forstå menneskeligt sprog,

OCR – Definition, fordele, udfordringer og brugssager [Infographic]
OCR er en teknologi, der gør det muligt for maskiner at læse trykt tekst og billeder. Det bruges ofte i forretningsapplikationer, såsom digitalisering af dokumenter til opbevaring eller behandling, og i forbrugerapplikationer, såsom scanning af en kvittering for udgiftsgodtgørelse.

Staten med samtale AI 2022
Status for konversations AI 2022 Hvad er Conversational AI? En programmatisk og intelligent måde at tilbyde en samtaleoplevelse til at efterligne samtaler med ægte mennesker gennem digital og telekommunikation

Hvad er dataindsamling? Alt en nybegynder har brug for at vide
Intelligente #AI/ #ML-modeller er overalt, hvad enten det er, prædiktive sundhedsmodeller, proaktiv diagnose,

Hvad er datamærkning? Alt, hvad en nybegynder skal vide
Download Infographics Intelligente AI -modeller skal trænes grundigt for at kunne identificere mønstre, objekter og til sidst træffe pålidelige beslutninger. Dog er de uddannede