

Intelligente AI -modeller skal trænes grundigt for at kunne identificere mønstre, objekter og til sidst træffe pålidelige beslutninger. Imidlertid kan de uddannede data ikke fodres tilfældigt og skal mærkes for at hjælpe modellerne med at forstå, behandle og lære omfattende af de kuraterede inputmønstre.
Det er her datamærkning kommer ind som en handling med mærkning af oplysninger eller rettere metadata i henhold til et specifikt datasæt for at fokusere på at forstærke forståelsen af maskinerne. For at gøre det yderligere, kategoriserer datamærkning selektivt data, billeder, tekst, lyd, videoer og mønstre for at forbedre AI -implementeringer.
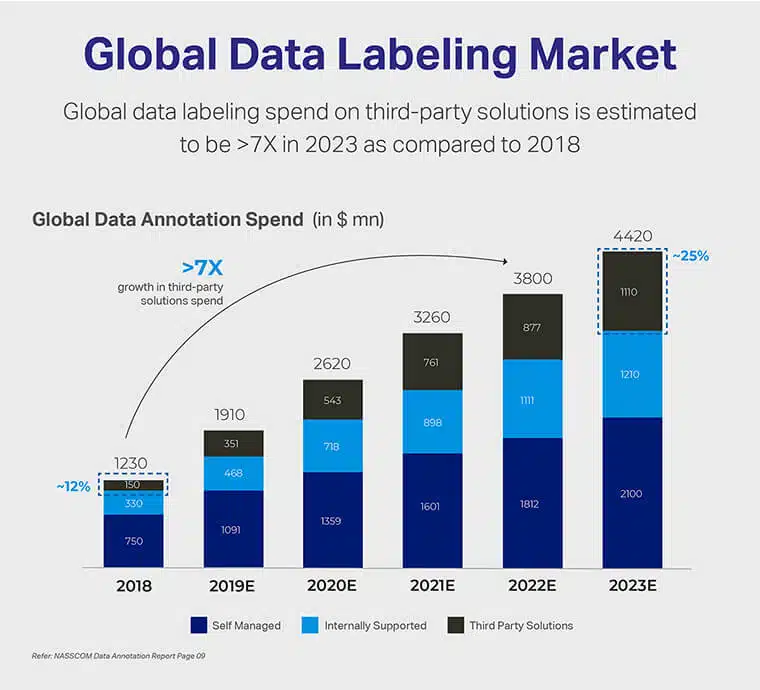
Som pr NASSCOM Datamærkning Rapport, det globale datamærkningsmarked forventes at vokse med 700% i værdi inden udgangen af 2023, sammenlignet med det i 2018. Denne påståede vækst vil sandsynligvis have betydning for den økonomiske tildeling til selvstyrede mærkeværktøjer, internt understøttet ressourcer og endda tredjepartsløsninger.
Ud over disse fund kan det også udledes, at det globale datamærkningsmarked samlede en værdi på $ 1.2 mia. I 2018. Vi forventer dog, at det skaleres, da datamærkningens markedsstørrelse formodes at nå en massiv værdiansættelse på $ 4.4 mia. inden 2023.
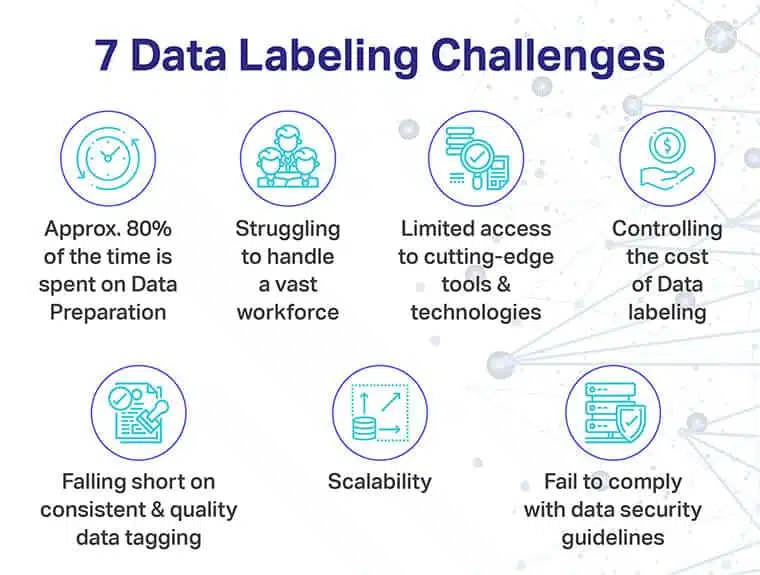
Datamærkning er timens behov, men der følger flere implementerings- og prisspecifikke udfordringer med.
Nogle af de mere presserende omfatter:
- Træg dataforberedelse, takket være redundante rengøringsværktøjer
- Mangel på nødvendig hardware til at håndtere en massiv arbejdsstyrke og overdreven mængde skrabet data
- Begrænset adgang til avantgarde-mærkningsværktøjer og understøttende teknologier
- Højere omkostninger ved datamærkning
- Manglende konsistens, når det drejer sig om kvalitetsdatamærkning
- Manglende skalerbarhed, hvis og når AI-modellen skal dække et ekstra sæt deltagere
- Manglende overholdelse, når det kommer til at opretholde en stabil datasikkerhedsstilling, mens du skaffer data og bruger dem

Selvom du kan adskille datamærkning konceptuelt, kræver de relevante værktøjer, at du klassificerer begreberne efter datasættets art. Disse omfatter:
- Audio klassifikation: Omfatter lydsamling, segmentering og transskription
- Billedmærkning: Består af indsamling, klassificering, segmentering og mærkning af nøglepunkter
- Tekstmærkning: Indeholder tekstudtræk og klassificering
- Videomærkning: Inkluderer elementer som videosamling, klassificering og segmentering
- 3D -mærkning: Indeholder objektsporing og segmentering
Bortset fra den førnævnte segregering, især fra et bredere perspektiv, er datamærkning opdelt i fire typer, herunder Descriptive, Evaluative, Informative og Combination al. Imidlertid er datamærkning adskilt som: Indsamling, Segmentering, Transkription, Klassificering, ekstraktion, objektsporing, som vi allerede har diskuteret for de enkelte datasæt.

Datamærkning er en detaljeret proces og involverer følgende trin til kategorisk at træne AI -modeller:
- Indsamling af datasæt via strategier, dvs. internt, open source, leverandører
- Mærkning af datasæt i henhold til Computer Vision, Deep learning og NLP-specifikke muligheder
- Test og evaluering af producerede modeller for at bestemme intelligens som en del af implementeringen
- Tilfredsstiller acceptabel modelkvalitet og frigiver den til sidst til omfattende brug

Det rigtige sæt datamærkeværktøjer, der er synonymt med en troværdig datamærkningsplatform, skal vælges ved at have følgende faktorer i tankerne:
- Type intelligens, du ønsker modellen skal have via definerede brugssager
- Kvalitet og erfaring med datakommentatorer, så de kan bruge værktøjerne til præcision
- Kvalitetsstandarder du har i tankerne
- Overholdelsesspecifikke behov
- Kommercielle værktøjer, open source og freeware-værktøjer
- Budget du kan spare
Ud over de nævnte faktorer er det bedre at holde øje med følgende overvejelser:
- Mærkning af værktøjernes nøjagtighed
- Kvalitetssikring garanteres af værktøjerne
- Integrationsmuligheder
- Sikkerhed og immunisering mod lækager
- Skybaseret opsætning eller ej
- Kvalitetskontrolstyring
- Fail-Safes, Stop-Gaps og skalerbar dygtighed af værktøjet
- Virksomheden tilbyder værktøjerne
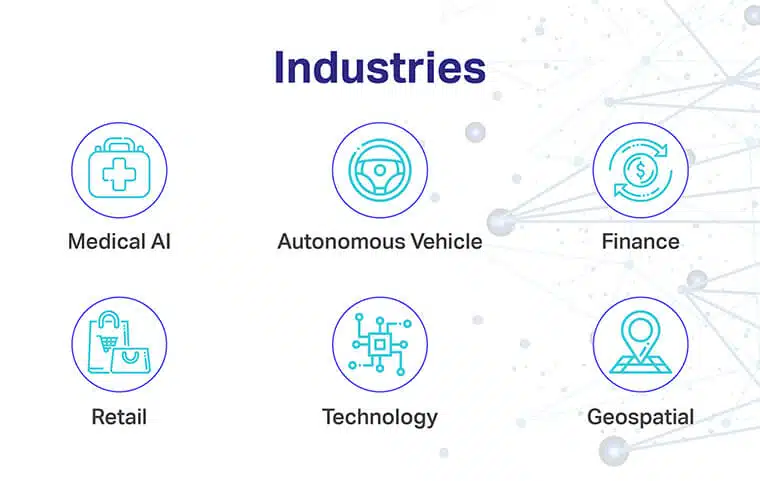
Vertikaler, der bedst tjent med værktøjer og ressourcer til datamærkning, omfatter:
- Medicinsk AI: Fokusområder omfatter træning af diagnostiske modeller med edb -vision til forbedret medicinsk billeddannelse, minimerede ventetider og minimal efterslæb
- Finans: Fokusområder omfatter evaluering af kreditrisici, låneberettigelse og andre vigtige faktorer via tekstmærkning
- Autonomt køretøj eller transport: Fokusområder omfatter implementering af NLP og Computer Vision til at stable modeller med en vanvittig mængde træningsdata til at detektere enkeltpersoner, signaler, blokader osv.
- Detail og e-handel: Fokusområder omfatter prisspecifikke beslutninger, forbedret e-handel, overvågning af købers persona, forståelse af købsvaner og forstærkning af brugeroplevelsen
- Teknologi: Fokusområder omfatter produktfremstilling, beholderplukning, påvisning af kritiske produktionsfejl på forhånd og mere
- Geospatial: Fokusområder omfatter GPS og fjernmåling ved hjælp af udvalgte mærkningsteknikker
- Landbrug: Fokusområder omfatter brug af GPS -sensorer, droner og computersyn til at fremme begreberne præcisionslandbrug, optimere jord- og afgrødeforhold, bestemme udbytter og mere

Stadig forvirret om, hvilken er en bedre strategi for at få datamærkning på sporet, dvs. Bygge et selvstyret setup eller købe et fra en tredjeparts tjenesteudbyder. Her er fordele og ulemper ved hver, der hjælper dig med at beslutte bedre:
'Byg' -apparatet
| Byg | KØB |
|---|---|
Hits:
| Hits:
|
Misses:
| Misses:
|
Fordele:
| Fordele:
|
Bedømmelse
Hvis du planlægger at bygge et eksklusivt AI -system uden at tiden er en begrænsning, giver det mening at bygge et mærkeværktøj fra bunden. For alt andet er det den bedste fremgangsmåde at købe et værktøj


