


Hvad er Conversational AI
Conversational AI er en avanceret form for kunstig intelligens, der gør det muligt for maskiner at indgå i interaktive, menneskelignende dialoger med brugerne. Denne teknologi forstår og fortolker menneskeligt sprog for at simulere naturlige samtaler. Det kan lære af interaktioner over tid for at reagere kontekstuelt.
Konversations-AI-systemer er meget brugt i applikationer som chatbots, stemmeassistenter og kundesupportplatforme på tværs af digitale og telekommunikationskanaler.
Konversations-AI-markedet har oplevet hurtig vækst i de seneste år. Oprindeligt udviklet til underholdningsformål, er konversations-AI blevet en integreret del af det digitale økosystem. Her er nogle nøglestatistikker for at illustrere dens virkning:
- Det globale konversations-AI-marked blev vurderet til $6.8 milliarder i 2021 og forventes at vokse til $18.4 milliarder i 2026 ved en CAGR på 22.6%. I 2028 forventes markedsstørrelsen at nå $ 29.8 milliarder.
- På trods af dens udbredelse, 63 % af brugerne er uvidende om, at de bruger kunstig intelligens i deres daglige liv.
- A Gartner-undersøgelse fandt, at mange virksomheder identificerede chatbots som deres primære AI-applikation, hvor næsten 70 % af funktionærerne forventes at interagere med samtaleplatforme dagligt i 2022.
- Siden pandemien er mængden af interaktioner, der håndteres af samtaleagenter, steget med lige så meget som 250 % på tværs af flere brancher.
- Andelen af marketingfolk, der bruger kunstig intelligens til digital markedsføring på verdensplan steg dramatisk fra 29 % i 2018 til 84% i 2020.
- I 2022, blev 91 % af voksne stemmeassistentbrugere brugte samtale-AI-teknologi på deres smartphones.
- Gennemse og søge efter produkter var de top shopping aktiviteter udført ved hjælp af stemmeassistentteknologi blandt amerikanske brugere i en undersøgelse fra 2021.
- Blandt tekniske fagfolk verden over, næsten 80 % bruge virtuelle assistenter til kundeservice.
- I 2024 mener 73 % af de nordamerikanske kundeservicebeslutningstagere, at onlinechat, videochat, chatbots eller sociale medier vil være mest brugte kundeservicekanaler.
- I en undersøgelse fra 2021, 86 % af amerikanske ledere blev enige om, at kunstig intelligens ville blive en "mainstream-teknologi" i deres virksomhed.
- Fra februar 2022, 53 % af amerikanske voksne havde kommunikeret med en AI-chatbot til kundeservice i det sidste år.
- I 2022, blev 3.5 milliarder chatbot-apps blev tilgået over hele verden.
- top tre grunde Amerikanske forbrugere bruger en chatbot til åbningstider (18%), produktinformation (17%) og kundeserviceanmodninger (16%).
Disse statistikker fremhæver den stigende indførelse og indflydelse af samtale-AI på tværs af forskellige industrier og forbrugeradfærd.
Hvordan fungerer Conversational AI
Conversational AI bruger naturlig sprogbehandling (NLP) og andre sofistikerede algoritmer til at indgå i kontekstrige dialoger. Efterhånden som AI møder et bredere udvalg af brugerinput, forbedrer det dets mønstergenkendelse og forudsigelsesevner. Processen med samtale-AI, der interagerer med brugere, kan opdeles i fire nøgletrin:

Trin 1: Indsamling af input – Brugere giver deres input enten via tekst eller stemme.
Trin 2: Inputbehandling – Når input er i tekstform, bruges naturlig sprogforståelse (NLU) til at udtrække mening fra ordene. Til stemmeinput anvendes automatisk talegenkendelse (ASR) først til at konvertere lyd til sprogtokens, der kan analyseres yderligere.
Trin 3: Generering af svar – Naturlige sproggenereringsteknikker bruges til at reagere korrekt på brugerens forespørgsel.
Trin 4: Kontinuerlig forbedring – Konversations-AI-systemer analyserer brugerinput over tid og forfiner deres svar for at sikre nøjagtighed og relevans.

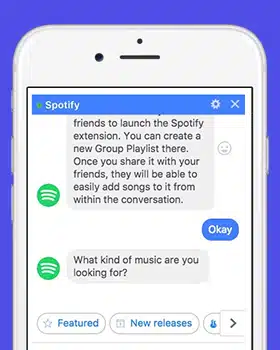
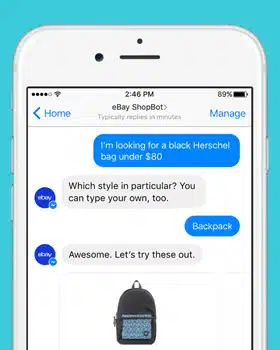

Afbød almindelige dataudfordringer i Conversational AI
Conversational AI transformerer dynamisk kommunikation mellem mennesker og computere. Og mange virksomheder er ivrige efter at udvikle avancerede AI-værktøjer og applikationer til samtale, der kan ændre, hvordan forretninger foregår. Men før du udvikler en chatbot, der kan facilitere en bedre kommunikation mellem dig og dine kunder, skal du se på de mange udviklingsmæssige faldgruber, du kan komme ud for.
Sprogmangfoldighed
 Det er udfordrende at udvikle en chatassistent, der kan henvende sig til flere sprog. Derudover gør den store mangfoldighed af globale sprog det til en udfordring at udvikle en chatbot, der problemfrit yder kundeservice til alle kunder.
Det er udfordrende at udvikle en chatassistent, der kan henvende sig til flere sprog. Derudover gør den store mangfoldighed af globale sprog det til en udfordring at udvikle en chatbot, der problemfrit yder kundeservice til alle kunder.
I 2022, blev omkring 1.5 mia mennesker talte engelsk på verdensplan, efterfulgt af kinesisk mandarin med 1.1 milliarder talere. Selvom engelsk er det mest talte og studerede fremmedsprog globalt, kun ca 20 % af verdens befolkning taler det. Det får resten af den globale befolkning – 80 % – til at tale andre sprog end engelsk. Så når du udvikler en chatbot, skal du også overveje sproglig mangfoldighed.
Sprogvariabilitet
Mennesker taler forskellige sprog og det samme sprog forskelligt. Desværre er det stadig umuligt for en maskine fuldt ud at forstå talesprogsvariabilitet, idet der tages hensyn til følelser, dialekter, udtale, accenter og nuancer.
Vores ord og sprogvalg afspejles også i, hvordan vi skriver. En maskine kan kun forventes at forstå og værdsætte sprogets variation, når en gruppe annotatorer træner den på forskellige taledatasæt.
Dynamik i tale
En anden stor udfordring i udviklingen af en samtale-AI er at bringe taledynamik ind i kampen. For eksempel bruger vi flere fyldstoffer, pauser, sætningsfragmenter og ukodelige lyde, når vi taler. Derudover er tale meget mere kompleks end det skrevne ord, da vi normalt ikke holder pause mellem hvert ord og understreger den rigtige stavelse.
Når vi lytter til andre, har vi en tendens til at udlede hensigten og meningen med deres samtale ved at bruge vores livserfaringer. Som et resultat heraf kontekstualiserer og forstår vi deres ord, selv når det er tvetydigt. Men en maskine er ude af stand til denne kvalitet.
Støjende data
Støjende data eller baggrundsstøj er data, der ikke giver værdi til samtalerne, såsom dørklokker, hunde, børn og andre baggrundslyde. Derfor er det vigtigt at skrubbe eller filtrere lydfiler af disse lyde og træne AI-systemet til at identificere de lyde, der betyder noget, og dem, der ikke gør.
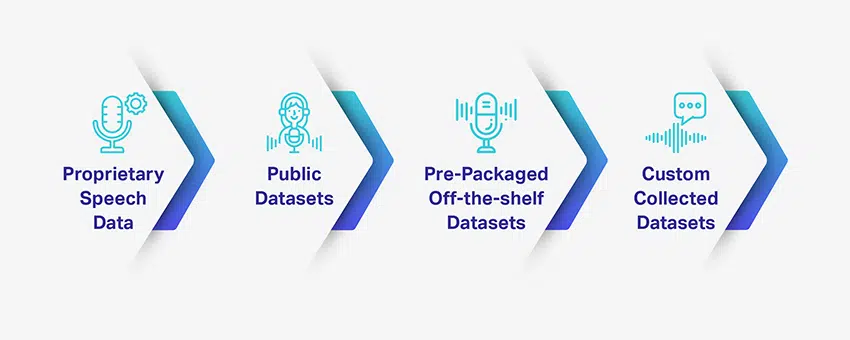
Fordele og ulemper ved forskellige taledatatyper
 Opbygning af et AI-drevet stemmegenkendelsessystem eller en samtale-AI kræver tonsvis af trænings- og testdatasæt. Det er dog ikke let at have adgang til sådanne kvalitetsdatasæt – pålidelige og opfylder dine specifikke projektbehov. Alligevel er der muligheder tilgængelige for virksomheder, der leder efter træningsdatasæt, og hver mulighed har fordele og ulemper.
Opbygning af et AI-drevet stemmegenkendelsessystem eller en samtale-AI kræver tonsvis af trænings- og testdatasæt. Det er dog ikke let at have adgang til sådanne kvalitetsdatasæt – pålidelige og opfylder dine specifikke projektbehov. Alligevel er der muligheder tilgængelige for virksomheder, der leder efter træningsdatasæt, og hver mulighed har fordele og ulemper.
Hvis du leder efter en generisk datasættype, har du masser af offentlige talemuligheder tilgængelige. Men for noget mere specifikt og relevant for dit projektkrav, skal du muligvis indsamle og tilpasse det på egen hånd.
Proprietære taledata
Det første sted at søge ville være din virksomheds proprietære data. Men da du har den juridiske ret og samtykke til at bruge dine kundetaledata, kan du være i stand til at bruge dette massive datasæt til træning og afprøvning af dine projekter.
Fordele:
- Ingen yderligere omkostninger til indsamling af træningsdata
- Træningsdataene er sandsynligvis relevante for din virksomhed
- Taledata har også naturlig baggrundsakustik, dynamiske brugere og enheder.
Ulemper:
- Brug af sådanne data kan koste dig et væld af penge på tilladelse til at optage og bruge.
- Taledataene kan have sproglige, demografiske eller kundebasebegrænsninger
- Data er muligvis gratis, men du betaler stadig for behandlingen, transskriptionen, tagging og mere.
Offentlige datasæt
Offentlige taledatasæt er en anden mulighed, hvis du ikke har til hensigt at bruge dit. Disse datasæt er en del af det offentlige domæne og kunne indsamles til open source-projekter.
FORDELE:
- Offentlige datasæt er gratis og ideelle til lavbudgetprojekter
- De er tilgængelige til download med det samme
- Offentlige datasæt kommer i en række scriptede og unscripted prøvesæt.
ULEMPER:
- Omkostningerne til behandling og kvalitetssikring kan være høje
- Kvaliteten af offentlige taledatasæt varierer i betydelig grad
- De tilbudte taleeksempler er normalt generiske, hvilket gør dem uegnede til at udvikle specifikke taleprojekter
- Datasættene er typisk skæve til det engelske sprog
Forpakkede/hyldevaredatasæt
Udforsk færdigpakkede datasæt er en anden mulighed, hvis offentlige data eller proprietære indsamling af taledata passer ikke til dine behov.
Sælgeren har indsamlet færdigpakkede taledatasæt med det specifikke formål at videresælge til kunder. Denne type datasæt kan bruges til at udvikle generiske applikationer eller specifikke formål.
FORDELE:
- Du får muligvis adgang til et datasæt, der passer til dit specifikke behov for taledata
- Det er mere overkommeligt at bruge et færdigpakket datasæt end at samle dit eget
- Du kan muligvis hurtigt få adgang til datasættet
ULEMPER:
- Da datasættet er færdigpakket, er det ikke tilpasset dit projektbehov.
- Desuden er datasættet ikke unikt for din virksomhed, da enhver anden virksomhed kan købe det.
Vælg brugerdefinerede indsamlede datasæt
Når du bygger en taleapplikation, vil du kræve et træningsdatasæt, der opfylder alle dine specifikke krav. Det er dog højst usandsynligt, at du får adgang til et færdigpakket datasæt, der imødekommer de unikke krav til dit projekt. Den eneste tilgængelige mulighed ville være at oprette dit datasæt eller anskaffe datasættet gennem tredjepartsløsningsudbydere.
Datasættene til dine trænings- og testbehov kan tilpasses fuldstændigt. Du kan inkludere sprogdynamik, taledatavariation og adgang til forskellige deltagere. Derudover kan datasættet skaleres til at opfylde dine projektkrav til tiden.
FORDELE:
- Datasæt indsamles til din specifikke brugssag. Chancen for, at AI-algoritmer afviger fra de tilsigtede resultater, er minimeret.
- Styr og reducer bias i AI-data
ULEMPER:
- Datasættene kan være dyre og tidskrævende; men fordelene opvejer altid omkostningerne.

Industrier, der bruger Conversational AI
I øjeblikket bliver konversations-AI overvejende brugt som Chatbots. Men flere industrier implementerer denne teknologi for at opnå enorme fordele. Nogle af de industrier, der bruger konversations-AI er:
Medicinal
 Conversational AI har en enorm indflydelse på sundhedssektoren. Conversational AI har vist sig at være gavnlig for patienter, læger, personale, sygeplejersker og andet medicinsk personale.
Conversational AI har en enorm indflydelse på sundhedssektoren. Conversational AI har vist sig at være gavnlig for patienter, læger, personale, sygeplejersker og andet medicinsk personale.
Nogle af fordelene er
- Patientinddragelse i efterbehandlingsfasen
- Chatbots til planlægning af aftaler
- Besvarelse af ofte stillede spørgsmål og generelle henvendelser
- Symptomvurdering
- Identificer kritiske patienter
- Eskalering af akutte tilfælde
ecommerce
 Conversational AI hjælper e-handelsvirksomheder med at engagere sig med deres kunder, give tilpassede anbefalinger og sælge produkter.
Conversational AI hjælper e-handelsvirksomheder med at engagere sig med deres kunder, give tilpassede anbefalinger og sælge produkter.
E-handelsindustrien udnytter fordelene ved denne bedste teknologi i klassen.
- Indsamling af kundeoplysninger
- Giv relevant produktinformation og anbefalinger
- Forbedring af kundetilfredsheden
- Hjælpe med at afgive ordrer og returnere
- Svar på ofte stillede spørgsmål
- Kryds- og mersalg af produkter
Bank
 Banksektoren implementerer samtale-AI-værktøjer for at forbedre kundeinteraktioner, behandle anmodninger i realtid og give en forenklet og samlet kundeoplevelse på tværs af flere kanaler.
Banksektoren implementerer samtale-AI-værktøjer for at forbedre kundeinteraktioner, behandle anmodninger i realtid og give en forenklet og samlet kundeoplevelse på tværs af flere kanaler.
- Giv kunderne mulighed for at tjekke deres saldi i realtid
- Hjælp med indskud
- Hjælpe med at indgive skat og ansøge om lån
- Strømlin bankprocessen ved at sende fakturapåmindelser, notifikationer og advarsler
Forsikring
 I lighed med banksektoren bliver forsikringsindustrien også digitalt drevet af konversations-AI og høster fordelene heraf. For eksempel hjælper samtale-AI forsikringsbranchen med at levere hurtigere og mere pålidelige midler til at løse konflikter og krav.
I lighed med banksektoren bliver forsikringsindustrien også digitalt drevet af konversations-AI og høster fordelene heraf. For eksempel hjælper samtale-AI forsikringsbranchen med at levere hurtigere og mere pålidelige midler til at løse konflikter og krav.
- Giv politiske anbefalinger
- Hurtigere skadeafvikling
- Fjern ventetider
- Indsaml feedback og anmeldelser fra kunder
- Skab kundebevidsthed om politikker
- Administrer hurtigere krav og fornyelse

Shaip Offer
Når det kommer til at levere kvalitet og pålidelige datasæt til udvikling af avancerede menneske-maskine interaktion taleapplikationer, har Shaip været førende på markedet med sine succesfulde implementeringer. Men med en akut mangel på chatbots og taleassistenter søger virksomheder i stigende grad Shaip – markedslederens – tjenester til at levere tilpassede, nøjagtige og kvalitetsdatasæt til træning og test til AI-projekter.
Ved at kombinere naturlig sprogbehandling kan vi give personlige oplevelser ved at hjælpe med at udvikle nøjagtige taleapplikationer, der efterligner menneskelige samtaler effektivt. Vi bruger en række avancerede teknologier til at levere kundeoplevelser af høj kvalitet. NLP lærer maskiner at fortolke menneskelige sprog og interagere med mennesker.
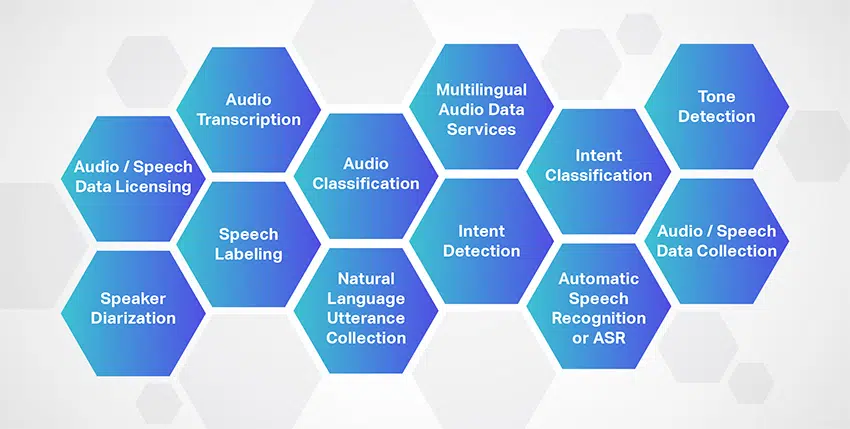
Lydtranskription
Shaip er en førende udbyder af lydtransskriptionstjenester, der tilbyder en række forskellige tale-/lydfiler til alle typer projekter. Derudover tilbyder Shaip en 100 % menneskeskabt transskriptionstjeneste til at konvertere lyd- og videofiler – interviews, seminarer, foredrag, podcasts osv. til letlæselig tekst.
Talemærkning
Shaip tilbyder omfattende talemærkningstjenester ved ekspertise at adskille lyde og tale i en lydfil og mærke hver fil. Ved nøjagtigt at adskille lignende lydlyde og annotere dem,
Højttaler-diarisering
Sharps ekspertise strækker sig til at tilbyde fremragende højttalerdiariseringsløsninger ved at segmentere lydoptagelsen baseret på deres kilde. Ydermere er højttalergrænserne nøjagtigt identificeret og klassificeret, såsom højttaler 1, højttaler 2, musik, baggrundsstøj, køretøjslyde, stilhed og mere for at bestemme antallet af højttalere.
Audio Klassificering
Annotering begynder med at klassificere lydfiler i forudbestemte kategorier. Kategorierne afhænger primært af projektets krav, og de omfatter typisk brugerhensigt, sprog, semantisk segmentering, baggrundsstøj, det samlede antal talere med mere.
Natural Language Ytring Collection/ Wake-up Words
Det er svært at forudsige, at klienten altid vil vælge lignende ord, når han stiller et spørgsmål eller indleder en anmodning. F.eks. "Hvor er den nærmeste restaurant?" "Find restauranter i nærheden af mig" eller "Er der en restaurant i nærheden?"
Alle tre ytringer har samme hensigt, men er formuleret forskelligt. Gennem permutation og kombination vil de eksperter til samtale-ai-specialister hos Shaip identificere alle de mulige kombinationer, der er mulige for at formulere den samme anmodning. Shaip indsamler og kommenterer ytringer og vækkeord med fokus på semantik, kontekst, tone, diktion, timing, stress og dialekter.
Flersprogede lyddatatjenester
Flersprogede lyddatatjenester er et andet meget foretrukket tilbud fra Shaip, da vi har et team af dataindsamlere, der indsamler lyddata på over 150 sprog og dialekter over hele kloden.
Intentionsdetektion
Menneskelig interaktion og kommunikation er ofte mere kompliceret, end vi giver dem æren for. Og denne medfødte komplikation gør det svært at træne en ML-model til at forstå menneskelig tale nøjagtigt.
Desuden kan forskellige mennesker fra den samme demografiske eller forskellige demografiske grupper udtrykke den samme hensigt eller følelse forskelligt. Så talegenkendelsessystemet skal trænes til at genkende fælles hensigter uanset demografi.
For at sikre, at du kan træne og udvikle en førsteklasses ML-model, leverer vores logopæder omfattende og forskelligartede datasæt for at hjælpe systemet med at identificere de forskellige måder, mennesker udtrykker den samme hensigt på.
Hensigtsklassifikation
I lighed med at identificere den samme hensigt fra forskellige mennesker, bør dine chatbots også trænes til at kategorisere kundekommentarer i forskellige kategorier - forudbestemt af dig. Hver chatbot eller virtuel assistent er designet og udviklet med et specifikt formål. Shaip kan klassificere brugerhensigt i foruddefinerede kategorier efter behov.
Automatisk talegenkendelse eller ASR
Talegenkendelse” refererer til at konvertere talte ord til teksten; dog sigter stemmegenkendelse og højttaleridentifikation på at identificere både talt indhold og højttalerens identitet. ASR's nøjagtighed bestemmes af forskellige parametre, dvs. højttalervolumen, baggrundsstøj, optageudstyr mv.
Toneregistrering
En anden interessant facet af menneskelig interaktion er tone - vi genkender iboende betydningen af ord afhængigt af den tone, som de udtales med. Selvom det, vi siger, er vigtigt, giver den måde, vi siger disse ord, også mening på.
For eksempel en simpel sætning som "Sikke en glæde!" kunne være et udråb om lykke og kunne også have til hensigt at være sarkastisk. Det afhænger af tonen og stress.
'Hvad laver du?'
'Hvad laver du?'
Begge disse sætninger har de nøjagtige ord, men belastningen på ordene er forskellig, hvilket ændrer hele betydningen af sætningerne. Chatbotten er trænet til at identificere lykke, sarkasme, vrede, irritation og flere udtryk. Det er her ekspertisen hos Sharps talesprogpatologer og annotatorer kommer i spil.
Lyd-/taledatalicens
Shaip tilbyder uovertrufne taledatasæt af hyldekvalitet, der kan tilpasses, så de passer til dit projekts specifikke behov. De fleste af vores datasæt kan passe ind i ethvert budget, og dataene er skalerbare til at imødekomme alle fremtidige projektkrav. Vi tilbyder mere end 40 timers hyldedatasæt på mere end 100 dialekter på over 50 sprog. Vi tilbyder også en række lydtyper, herunder spontane, monologe, scriptede ord og vækkeord. Se det hele Datakatalog.
Indsamling af lyd-/taledata
Når der er mangel på kvalitetstaledatasæt, kan den resulterende taleløsning være fyldt med problemer og mangle pålidelighed. Shaip er en af de få udbydere, der leverer flersprogede lydsamlinger, lydtransskription og annotationsværktøjer og tjenester, der kan tilpasses fuldt ud til projektet.
Taledata kan ses som et spektrum, der går fra naturlig tale i den ene ende til unaturlig tale i den anden. I naturlig tale har du taleren til at tale på en spontan samtalemåde. På den anden side lyder unaturlig tale begrænset, når taleren læser et manuskript. Til sidst bliver talerne bedt om at udtale ord eller sætninger på en kontrolleret måde midt i spektret.
Sharps ekspertise strækker sig til at levere forskellige typer taledatasæt på over 150 sprog

































Succeshistorier
Vi har arbejdet med nogle af de bedste virksomheder og brands og har forsynet dem med samtale-AI-løsninger af højeste orden.
Nogle af vores succeshistorier inkluderer,
- Vi havde udviklet et talegenkendelsesdatasæt med mere end 10,000 timers flersprogede transskriptioner, samtaler og lydfiler til at træne og bygge en live chatbot.
- Vi byggede et datasæt af høj kvalitet med 1000-vis af samtaler på 6 omgange pr. samtale, der bruges til forsikrings-chatbot-træning.
- Vores team på 3000 plus sprogeksperter leverede mere end 1000 timers lydfiler og transskriptioner på 27 modersmål til træning og test af en digital assistent.
- Vores team af annotatorer og sprogeksperter indsamlede og leverede også 20,000 og flere timers ytringer på mere end 27 globale sprog hurtigt.
- Vores automatiske talegenkendelsestjenester er en af de mest foretrukne af branchen. Vi leverede pålideligt mærkede lydfiler, der sikrede specifik opmærksomhed på udtale, tone og hensigt ved at bruge en bred vifte af transskriptioner og leksikon fra forskellige højttalersæt for at forbedre pålideligheden af ASR-modeller.
Vores succeshistorier stammer fra vores teams forpligtelse til altid at levere den bedste service ved hjælp af de nyeste teknologier til vores kunder. Det, der gør os anderledes, er, at vores arbejde understøttes af ekspertannotatorer, som leverer upartiske og nøjagtige datasæt af guldstandard-annoteringer.
Vores dataindsamlingsteam på over 30,000 bidragydere kan hente, skalere og levere datasæt af høj kvalitet, der hjælper med hurtig implementering af ML-modeller. Derudover arbejder vi på den nyeste AI-baserede platform og har mulighed for at levere accelererede taledataløsninger til virksomheder meget hurtigere end vores nærmeste konkurrenter.
