
Introduktion
Denne vejledning vil være yderst hjælpsom for de købere og beslutningstagere, der begynder at vende deres tanker mod møtrikker og bolte ved datasourcing og dataimplementering både til neurale netværk og andre typer AI- og ML-operationer.

Denne artikel er helt dedikeret til at kaste lys over, hvad processen er, hvorfor den er uundgåelig, afgørende
faktorer, virksomheder bør overveje, når de nærmer sig værktøjer til dataanmelding og mere. Så hvis du ejer en virksomhed, skal du gøre dig klar til at blive oplyst, da denne guide vil guide dig gennem alt, hvad du har brug for at vide om datakommentarer.
Lad os komme igang.
For dem af jer, der læser artiklen igennem, er her nogle hurtige takeaways, du finder i guiden:
- Forstå hvad datanotering er
- Kend de forskellige typer af data-annoteringsprocesser
- Kend fordelene ved at implementere dataanmeldingsprocessen
- Få klarhed over, om du skal gå til intern datamærkning eller få dem outsourcet
- Indsigt i at vælge den rigtige datanotering også
Hvad er maskinlæring?
 Vi har talt om, hvordan dataannotering eller datamærkning understøtter maskinlæring, og at den består af mærkning eller identifikation af komponenter. Men hvad angår dyb læring og selve maskinlæringen: Den grundlæggende forudsætning for maskinlæring er, at computersystemer og programmer kan forbedre deres output på måder, der ligner menneskelige kognitive processer, uden direkte menneskelig hjælp eller indgriben, for at give os indsigt. Med andre ord bliver de til selvlærende maskiner, der ligesom et menneske bliver bedre til deres job med mere øvelse. Denne "praksis" opnås ved at analysere og fortolke flere (og bedre) træningsdata.
Vi har talt om, hvordan dataannotering eller datamærkning understøtter maskinlæring, og at den består af mærkning eller identifikation af komponenter. Men hvad angår dyb læring og selve maskinlæringen: Den grundlæggende forudsætning for maskinlæring er, at computersystemer og programmer kan forbedre deres output på måder, der ligner menneskelige kognitive processer, uden direkte menneskelig hjælp eller indgriben, for at give os indsigt. Med andre ord bliver de til selvlærende maskiner, der ligesom et menneske bliver bedre til deres job med mere øvelse. Denne "praksis" opnås ved at analysere og fortolke flere (og bedre) træningsdata.
Hvad er datanotering?
Dataannotering er processen med at tilskrive, tagge eller mærke data for at hjælpe maskinlæringsalgoritmer med at forstå og klassificere de oplysninger, de behandler. Denne proces er essentiel for at træne AI-modeller, hvilket gør dem i stand til præcist at forstå forskellige datatyper, såsom billeder, lydfiler, videooptagelser eller tekst.
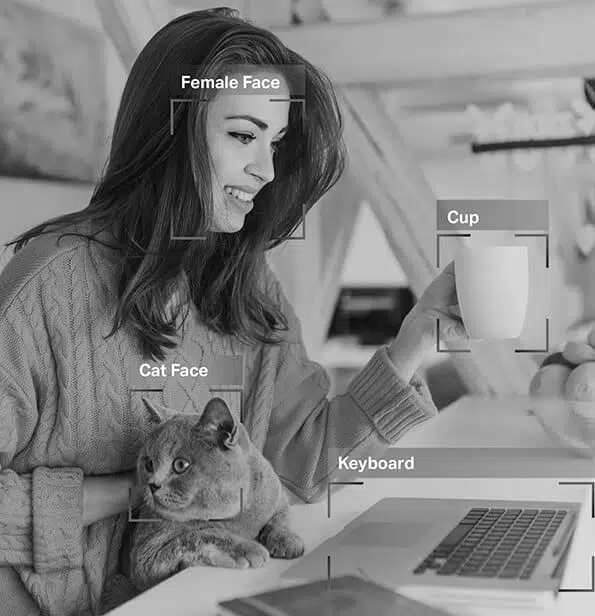
Forestil dig en selvkørende bil, der er afhængig af data fra computersyn, naturlig sprogbehandling (NLP) og sensorer til at træffe nøjagtige kørselsbeslutninger. For at hjælpe bilens AI-model med at skelne mellem forhindringer som andre køretøjer, fodgængere, dyr eller vejspærringer, skal de data, den modtager, mærkes eller kommenteres.
I overvåget læring er dataannotering især afgørende, da jo mere mærkede data der tilføres modellen, jo hurtigere lærer den at fungere autonomt. Annoterede data gør det muligt at implementere AI-modeller i forskellige applikationer som chatbots, talegenkendelse og automatisering, hvilket resulterer i optimal ydeevne og pålidelige resultater.
Hvad er et værktøj til datamærkning/annotering?
 Enkelt sagt er det en platform eller en portal, der lader specialister og eksperter kommentere, mærke eller mærke datasæt af alle typer. Det er en bro eller et mellemrum mellem rådata og de resultater, dine maskinlæringsmoduler i sidste ende ville slå ud.
Enkelt sagt er det en platform eller en portal, der lader specialister og eksperter kommentere, mærke eller mærke datasæt af alle typer. Det er en bro eller et mellemrum mellem rådata og de resultater, dine maskinlæringsmoduler i sidste ende ville slå ud.
Et datamærkeværktøj er en on-prem eller cloud-baseret løsning, der kommenterer træningsdata af høj kvalitet til maskinlæringsmodeller. Mens mange virksomheder er afhængige af en ekstern leverandør til at lave komplekse annoteringer, har nogle organisationer stadig deres egne værktøjer, der enten er specialfremstillede eller er baseret på freeware- eller opensource-værktøjer, der er tilgængelige på markedet. Sådanne værktøjer er normalt designet til at håndtere specifikke datatyper, f.eks. Billede, video, tekst, lyd osv. Værktøjerne tilbyder funktioner eller muligheder som afgrænsningsbokse eller polygoner til datakommentatorer til at mærke billeder. De kan bare vælge indstillingen og udføre deres specifikke opgaver.
Billedannotation

Fra de datasæt, de er blevet undervist i, kan de øjeblikkeligt og præcist differentiere dine øjne fra din næse og dit øjenbryn fra dine øjenvipper. Derfor passer de filtre, du anvender, perfekt, uanset ansigtets form, hvor tæt du er på dit kamera og meget mere.
Så som du nu ved, billedkommentar er afgørende for moduler, der involverer ansigtsgenkendelse, computersyn, robotisk visning og mere. Når AI -eksperter træner sådanne modeller, tilføjer de billedtekster, identifikatorer og søgeord som attributter til deres billeder. Algoritmerne identificerer og forstår derefter ud fra disse parametre og lærer autonomt.
Billedklassificering – Billedklassificering involverer at tildele foruddefinerede kategorier eller etiketter til billeder baseret på deres indhold. Denne type annotering bruges til at træne AI-modeller til at genkende og kategorisere billeder automatisk.
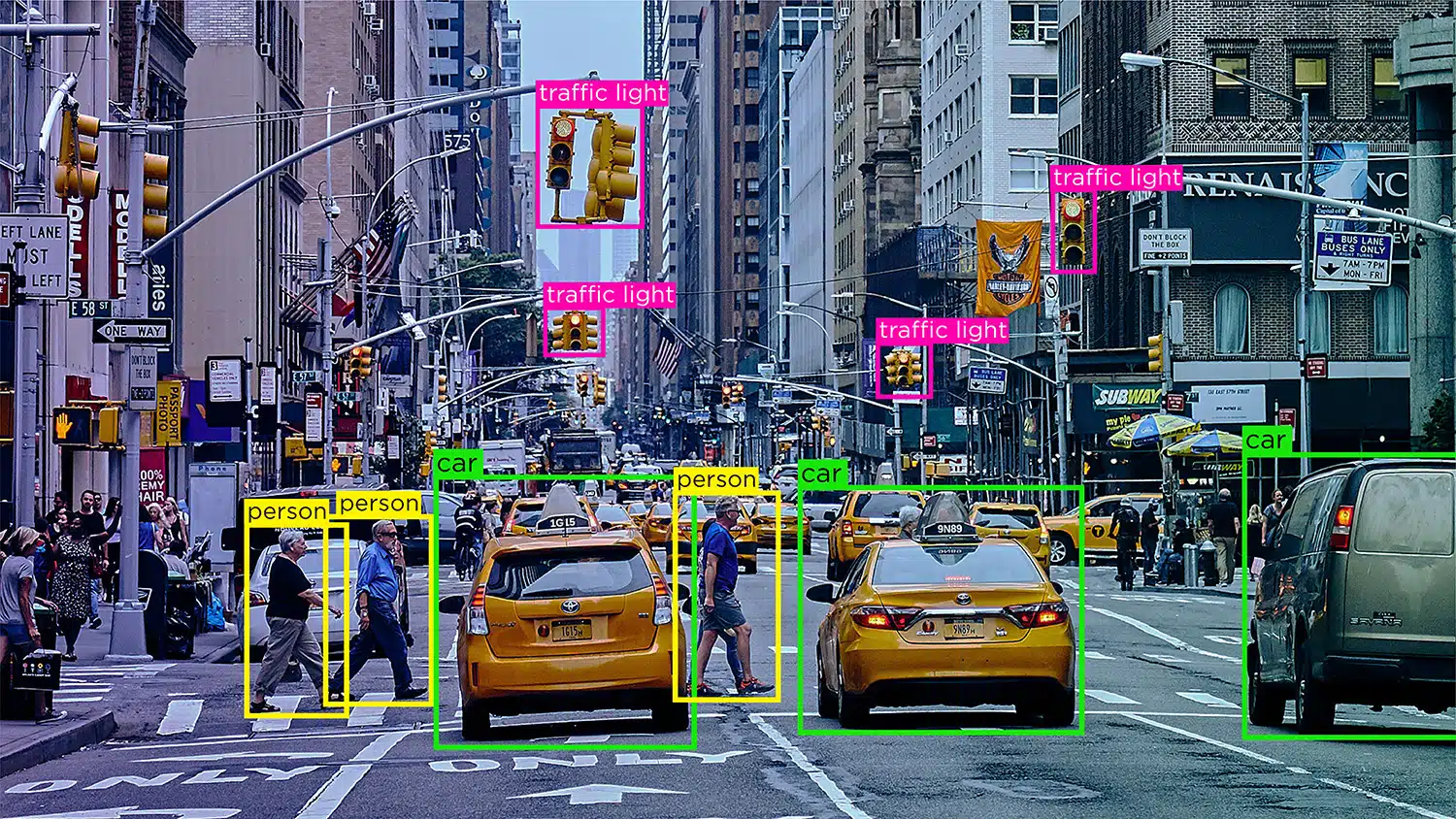
Objektgenkendelse/detektion – Objektgenkendelse eller objektgenkendelse er processen med at identificere og mærke specifikke objekter i et billede. Denne type annotering bruges til at træne AI-modeller til at lokalisere og genkende objekter i billeder eller videoer fra den virkelige verden.
Segmentering – Billedsegmentering involverer opdeling af et billede i flere segmenter eller områder, der hver svarer til et specifikt objekt eller område af interesse. Denne type annotering bruges til at træne AI-modeller til at analysere billeder på pixelniveau, hvilket muliggør mere nøjagtig genkendelse af objekter og sceneforståelse.
Lydkommentar
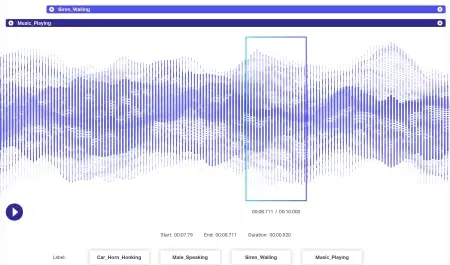
Lyddata har endnu mere dynamik knyttet til sig end billeddata. Flere faktorer er forbundet med en lydfil inklusive, men bestemt ikke begrænset til - sprog, højttalerdemografi, dialekter, humør, hensigt, følelser, opførsel. For at algoritmer skal være effektive i behandlingen, skal alle disse parametre identificeres og mærkes ved hjælp af teknikker som tidsstempling, lydmærkning og mere. Udover blot verbale signaler, kunne ikke-verbale tilfælde som stilhed, åndedrag, endda baggrundsstøj kommenteres for at systemerne kunne forstå det omfattende.
Video-kommentar

Mens et billede er stille, er en video en samling af billeder, der skaber en effekt af genstande, der er i bevægelse. Nu kaldes hvert billede i denne samling en ramme. For så vidt angår videoteknologi, involverer processen tilføjelsen af tastatur, polygoner eller afgrænsningsfelter for at kommentere forskellige objekter i marken i hver ramme.
Når disse rammer er syet sammen, kan bevægelsen, adfærden, mønstrene og mere læres af AI-modellerne i aktion. Det er kun igennem videoannotation at begreber som lokalisering, bevægelsessløring og objektsporing kunne implementeres i systemer.
Tekstkommentar

I dag er de fleste virksomheder afhængige af tekstbaserede data for unik indsigt og information. Nu kan tekst være alt lige fra kundefeedback på en app til en social medieomtale. Og i modsætning til billeder og videoer, der for det meste formidler intentioner, der er ligetil, kommer tekst med en masse semantik.
Som mennesker er vi indstillet på at forstå sammenhængen med en sætning, betydningen af hvert ord, sætning eller sætning, relatere dem til en bestemt situation eller samtale og derefter indse den holistiske betydning bag en erklæring. Maskiner kan derimod ikke gøre dette på præcise niveauer. Begreber som sarkasme, humor og andre abstrakte elementer er ukendte for dem, og derfor bliver tekstdatamærkning vanskeligere. Derfor har tekstkommentarer nogle mere raffinerede faser som følgende:
Semantisk kommentar - objekter, produkter og tjenester gøres mere relevante ved hjælp af passende nøglefrasemærkning og identifikationsparametre. Chatbots er også lavet til at efterligne menneskelige samtaler på denne måde.
Intent annotation - brugerens hensigt og det sprog, de bruger, er mærket for maskiner at forstå. Med dette kan modeller skelne mellem en anmodning fra en kommando eller anbefaling fra en reservation og så videre.
Følelsesanmærkning – Følelsesannotering involverer at mærke tekstdata med den stemning, den formidler, såsom positiv, negativ eller neutral. Denne type annotering er almindeligt anvendt i sentimentanalyse, hvor AI-modeller trænes til at forstå og evaluere de følelser, der udtrykkes i tekst.

Enhedskommentar - hvor ustrukturerede sætninger er mærket for at gøre dem mere meningsfulde og bringe dem til et format, der kan forstås af maskiner. For at få dette til at ske er to aspekter involveret - navngivet enhedsgenkendelse , enhedslinking. Navngivet enhedsgenkendelse er, når navne på steder, mennesker, begivenheder, organisationer og mere er tagget og identificeret, og enhedslinkning er, når disse tags er knyttet til sætninger, sætninger, fakta eller meninger, der følger dem. Samlet set etablerer disse to processer forholdet mellem de tilknyttede tekster og udsagnet omkring det.
Tekstkategorisering – Sætninger eller afsnit kan mærkes og klassificeres baseret på overordnede emner, tendenser, emner, meninger, kategorier (sport, underholdning og lignende) og andre parametre.
Nøgletrin i datamærkning og dataanmærkningsprocessen
Dataanmærkningsprocessen involverer en række veldefinerede trin for at sikre høj kvalitet og nøjagtig datamærkning til maskinlæringsapplikationer. Disse trin dækker alle aspekter af processen, fra dataindsamling til eksport af de kommenterede data til videre brug.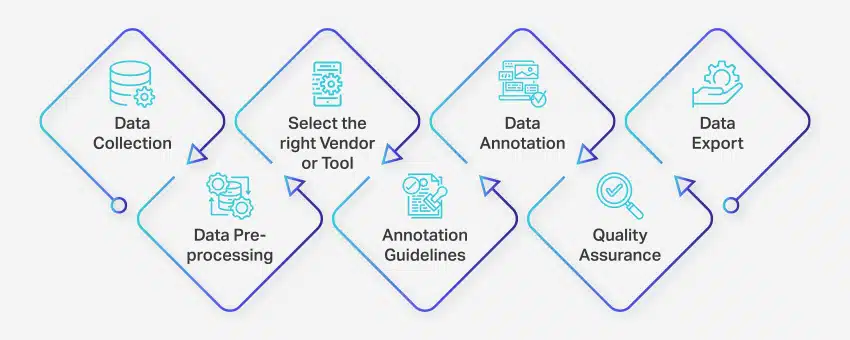
Sådan foregår dataannotering:
- Dataindsamling: Det første trin i dataanmærkningsprocessen er at samle alle relevante data, såsom billeder, videoer, lydoptagelser eller tekstdata, på et centralt sted.
- Dataforbehandling: Standardiser og forbedre de indsamlede data ved at rette billeder, formatere tekst eller transskribere videoindhold. Forbehandling sikrer, at dataene er klar til annotering.
- Vælg den rigtige leverandør eller værktøj: Vælg et passende dataanmærkningsværktøj eller leverandør baseret på dit projekts krav. Indstillinger omfatter platforme som Nanonets til dataannotering, V7 til billedannotering, Appen til videoannotering og Nanonets til dokumentannotering.
- Retningslinjer for anmærkninger: Etabler klare retningslinjer for annotatorer eller annoteringsværktøjer for at sikre konsistens og nøjagtighed gennem hele processen.
- Kommentar: Mærk og tag dataene ved hjælp af menneskelige annotatorer eller dataannoteringssoftware i henhold til de etablerede retningslinjer.
- Kvalitetssikring (QA): Gennemgå de annoterede data for at sikre nøjagtighed og konsistens. Anvend om nødvendigt flere blinde annoteringer for at verificere kvaliteten af resultaterne.
- Dataeksport: Når du har fuldført dataanmærkningen, skal du eksportere dataene i det påkrævede format. Platforme som Nanonets muliggør problemfri dataeksport til forskellige forretningssoftwareapplikationer.
Hele dataanmærkningsprocessen kan variere fra et par dage til flere uger, afhængigt af projektets størrelse, kompleksitet og tilgængelige ressourcer.
Funktioner til Data Annotation og Data Labelling Tools
Dataanotationsværktøjer er afgørende faktorer, der kan skabe eller bryde dit AI -projekt. Når det kommer til præcise output og resultater, er kvaliteten af datasæt alene ligegyldig. Faktisk påvirker de dataanmeldingsværktøjer, du bruger til at træne dine AI -moduler, enormt meget dine output.
Derfor er det vigtigt at vælge og bruge det mest funktionelle og passende datamærkeværktøj, der opfylder din virksomheds eller projektbehov. Men hvad er et dataannotationsværktøj i første omgang? Hvilket formål tjener det? Er der nogen typer? Lad os finde ud af det.
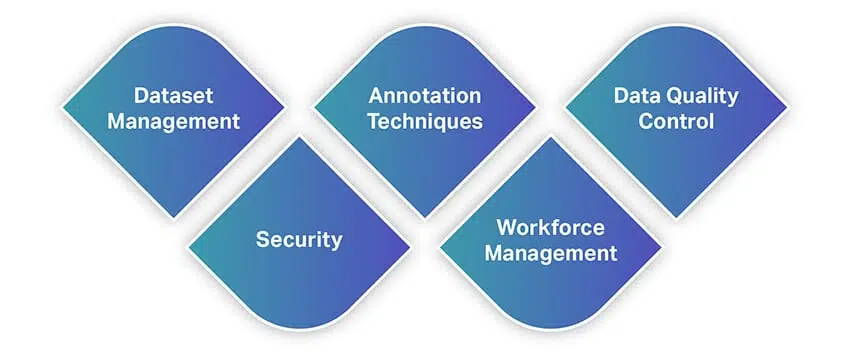
Ligesom andre værktøjer tilbyder dataanmeldingsværktøjer en lang række funktioner og muligheder. For at give dig en hurtig idé om funktioner, her er en liste over nogle af de mest grundlæggende funktioner, du skal kigge efter, når du vælger et dataanotationsværktøj.
Datasæt Management
Det dataanmeldingsværktøj, du agter at bruge, skal understøtte de datasæt, du har i hånden, og lade dig importere dem til softwaren til mærkning. Så administration af dine datasæt er det primære funktionsværktøjstilbud. Moderne løsninger tilbyder funktioner, der lader dig importere store datamængder problemfrit, samtidig med at du kan organisere dine datasæt gennem handlinger som sortering, filtrering, kloning, fletning og mere.
Når indtastningen af dine datasæt er udført, eksporterer vi dem som brugbare filer. Det værktøj, du bruger, skal lade dig gemme dine datasæt i det format, du angiver, så du kan føde dem til dine ML -modeller.
Annoteringsteknikker
Dette er, hvad et dataanmeldingsværktøj er bygget eller designet til. Et solidt værktøj bør tilbyde dig en række annoteringsteknikker til datasæt af alle typer. Dette er medmindre du udvikler en tilpasset løsning til dine behov. Dit værktøj skal lade dig kommentere video eller billeder fra computersyn, lyd eller tekst fra NLP'er og transskriptioner og mere. Ved at forfine dette yderligere, bør der være muligheder for at bruge afgrænsningsbokse, semantisk segmentering, kuboider, interpolation, sentimentanalyse, taledele, coreference -løsning og mere.
For de uindviede er der også AI-drevne dataanmeldingsværktøjer. Disse leveres med AI -moduler, der autonomt lærer af en annotators arbejdsmønstre og automatisk kommenterer billeder eller tekst. Sådan
moduler kan bruges til at yde utrolig hjælp til annotatorer, optimere annotationer og endda implementere kvalitetskontrol.
Datakvalitetskontrol
Når vi taler om kvalitetskontroller, ruller flere dataannotationsværktøjer derude ud med integrerede kvalitetskontrolmoduler. Disse giver annotatorer mulighed for at samarbejde bedre med deres teammedlemmer og hjælpe med at optimere arbejdsgange. Med denne funktion kan annotatorer markere og spore kommentarer eller feedback i realtid, spore identiteter bag mennesker, der foretager ændringer i filer, gendanne tidligere versioner, vælge etiketteringskonsensus og mere.
Sikkerhed
Da du arbejder med data, bør sikkerhed have højeste prioritet. Du arbejder muligvis med fortrolige data som dem, der involverer personlige oplysninger eller intellektuel ejendomsret. Så dit værktøj skal give lufttæt sikkerhed med hensyn til, hvor dataene gemmes, og hvordan de deles. Det skal levere værktøjer, der begrænser adgang til teammedlemmer, forhindrer uautoriserede downloads og mere.
Bortset fra disse skal sikkerhedsstandarder og protokoller overholdes og overholdes.
Arbejdsstyring
Et dataanmeldingsværktøj er også en slags projektstyringsplatform, hvor opgaver kan tildeles teammedlemmer, samarbejde kan ske, anmeldelser er mulige og mere. Derfor skal dit værktøj passe ind i din arbejdsgang og proces for optimeret produktivitet.
Desuden skal værktøjet også have en minimal indlæringskurve, da processen med dataanmelding i sig selv er tidskrævende. Det tjener ikke noget formål at bruge for meget tid på blot at lære værktøjet. Så det burde være intuitivt og problemfrit for alle at komme hurtigt i gang.
Hvad er fordelene ved dataannotering?
Dataannotering er afgørende for at optimere maskinlæringssystemer og levere forbedrede brugeroplevelser. Her er nogle af de vigtigste fordele ved dataannotering:
- Forbedret træningseffektivitet: Datamærkning hjælper maskinlæringsmodeller med at blive bedre trænet, hvilket øger den overordnede effektivitet og producerer mere præcise resultater.
- Øget præcision: Nøjagtigt annoterede data sikrer, at algoritmer kan tilpasse sig og lære effektivt, hvilket resulterer i højere niveauer af præcision i fremtidige opgaver.
- Reduceret menneskelig indgriben: Avancerede dataannoteringsværktøjer reducerer behovet for manuel indgriben markant, strømliner processer og reducerer tilknyttede omkostninger.
Dataannotering bidrager således til mere effektive og præcise maskinlæringssystemer, samtidig med at omkostningerne og den manuelle indsats, der traditionelt kræves for at træne AI-modeller, minimeres.
At bygge eller ikke oprette et dataanmærkningsværktøj
Et kritisk og overordnet problem, der kan komme op under et datanotering eller datamærkningsprojekt, er valget om enten at opbygge eller købe funktionalitet til disse processer. Dette kan komme op flere gange i forskellige projektfaser eller relateret til forskellige segmenter af programmet. Når du vælger, om du skal bygge et system internt eller stole på leverandører, er der altid en kompromis.

Som du sandsynligvis nu kan fortælle, er datanotering en kompleks proces. Samtidig er det også en subjektiv proces. Det betyder, at der ikke er et eneste svar på spørgsmålet om, hvorvidt du skal købe eller opbygge et dataanmærkningsværktøj. En masse faktorer skal overvejes, og du skal stille dig selv nogle spørgsmål for at forstå dine krav og indse, om du rent faktisk har brug for at købe eller bygge en.
For at gøre dette enkelt er her nogle af de faktorer, du bør overveje.
Dit mål
Det første element, du skal definere, er målet med din kunstige intelligens og maskinindlæringskoncepter.
- Hvorfor implementerer du dem i din virksomhed?
- Løser de et problem i den virkelige verden, som dine kunder står over for?
- Gør de nogen front-end eller backend-proces?
- Vil du bruge AI til at introducere nye funktioner eller optimere din eksisterende hjemmeside, app eller et modul?
- Hvad laver din konkurrent i dit segment?
- Har du nok brugssager, der har brug for AI-intervention?
Svarene på disse samler dine tanker - som i øjeblikket kan være overalt - på ét sted og giver dig mere klarhed.
AI -dataindsamling / -licensiering
AI -modeller kræver kun ét element for at fungere - data. Du er nødt til at identificere, hvorfra du kan generere enorme mængder jord-sandhedsdata. Hvis din virksomhed genererer store mængder data, der skal behandles for afgørende indsigt i forretning, drift, konkurrentundersøgelser, markedsvolatilitetsanalyse, undersøgelse af kundeadfærd og mere, har du brug for et dataanoteringsværktøj. Du bør dog også overveje mængden af data, du genererer. Som nævnt tidligere er en AI -model kun lige så effektiv som kvaliteten og mængden af data, den fodres med. Så dine beslutninger bør uvægerligt afhænge af denne faktor.
Hvis du ikke har de rigtige data til at træne dine ML-modeller, kan leverandører komme ret praktisk, og hjælpe dig med datalicensering af det rigtige datasæt, der kræves for at træne ML-modeller. I nogle tilfælde vil en del af den værdi, som sælgeren bringer, involvere både teknisk dygtighed og også adgang til ressourcer, der vil fremme projektsucces.
budget
En anden grundlæggende betingelse, der sandsynligvis påvirker hver eneste faktor, vi i øjeblikket diskuterer. Løsningen på spørgsmålet om, hvorvidt du skal oprette eller købe en datanotering, bliver let, når du forstår, om du har nok budget til at bruge.
Overholdelseskompleksiteter
 Leverandører kan være yderst nyttige, når det kommer til databeskyttelse og korrekt håndtering af følsomme data. En af disse typer brugssager involverer et hospital eller en sundhedsrelateret virksomhed, der ønsker at udnytte kraften i maskinindlæring uden at bringe dens overholdelse af HIPAA og andre databeskyttelsesregler i fare. Selv uden for det medicinske område strammer love som den europæiske GDPR kontrol over datasæt og kræver større opmærksomhed fra virksomhedens interessenter.
Leverandører kan være yderst nyttige, når det kommer til databeskyttelse og korrekt håndtering af følsomme data. En af disse typer brugssager involverer et hospital eller en sundhedsrelateret virksomhed, der ønsker at udnytte kraften i maskinindlæring uden at bringe dens overholdelse af HIPAA og andre databeskyttelsesregler i fare. Selv uden for det medicinske område strammer love som den europæiske GDPR kontrol over datasæt og kræver større opmærksomhed fra virksomhedens interessenter.
Manpower
Datakommentarer kræver dygtig arbejdskraft at arbejde på uanset størrelse, skala og domæne for din virksomhed. Selvom du genererer minimale data hver eneste dag, har du brug for dataeksperter til at arbejde med dine data til mærkning. Så nu skal du indse, om du har den nødvendige arbejdskraft på plads.Hvis du gør det, er de dygtige til de nødvendige værktøjer og teknikker, eller har de brug for efteruddannelse? Hvis de har brug for efteruddannelse, har du så budgettet til at uddanne dem i første omgang?
Desuden tager de bedste datanoteringer og datamærkningsprogrammer et antal emne- eller domæneeksperter og segmenterer dem i henhold til demografi som alder, køn og ekspertiseområde - eller ofte med hensyn til de lokaliserede sprog, de vil arbejde med. Det er igen, hvor vi i Shaip taler om at få de rigtige mennesker i de rigtige sæder og derved køre de rigtige menneskelige processer, der vil føre din programmatiske indsats til succes.
Små og store projektoperationer og omkostningstærskler
I mange tilfælde kan leverandørsupport være mere en mulighed for et mindre projekt eller for mindre projektfaser. Når omkostningerne er kontrollerbare, kan virksomheden drage fordel af outsourcing for at gøre datakommentarer eller datamærkningsprojekter mere effektive.
Virksomheder kan også se på vigtige tærskler - hvor mange leverandører binder omkostninger til mængden af forbrugt data eller andre ressourcebenchmarks. Lad os f.eks. Sige, at en virksomhed har tilmeldt sig en leverandør for at udføre den kedelige dataindtastning, der kræves for at oprette testsæt.
Der kan være en skjult tærskel i aftalen, hvor f.eks. Forretningspartneren skal fjerne en anden blok med AWS-datalagring eller en anden servicekomponent fra Amazon Web Services eller en anden tredjepartsleverandør. De videregiver det til kunden i form af højere omkostninger, og det sætter prislappen uden for kundens rækkevidde.
I disse tilfælde hjælper måling af de tjenester, du får fra leverandører, med at holde projektet overkommeligt. At have det rigtige omfang på plads vil sikre, at projektomkostningerne ikke overstiger det, der er rimeligt eller gennemførligt for det pågældende firma.
Open Source og freeware alternativer
 Nogle alternativer til fuld leverandørsupport involverer brug af open source-software eller endda freeware til at foretage datanotering eller mærkningsprojekter. Her er der en slags mellemvej, hvor virksomheder ikke skaber alt fra bunden, men også undgår at stole for stærkt på kommercielle leverandører.
Nogle alternativer til fuld leverandørsupport involverer brug af open source-software eller endda freeware til at foretage datanotering eller mærkningsprojekter. Her er der en slags mellemvej, hvor virksomheder ikke skaber alt fra bunden, men også undgår at stole for stærkt på kommercielle leverandører.
Gør-det-selv-mentaliteten af open source er i sig selv et slags kompromis - ingeniører og interne mennesker kan drage fordel af open source-samfundet, hvor decentrale brugerbaser tilbyder deres egen slags græsrodsstøtte. Det vil ikke være som hvad du får fra en leverandør - du får ikke 24/7 nem hjælp eller svar på spørgsmål uden at foretage intern forskning - men prislappen er lavere.
Så det store spørgsmål - Hvornår skal du købe et datanoteringsværktøj:
Som med mange slags højteknologiske projekter kræver denne type analyse - hvornår man skal bygge og hvornår man køber - dedikeret overvejelse og overvejelse af, hvordan disse projekter hentes og styres. De udfordringer, som de fleste virksomheder står over for i forbindelse med AI / ML-projekter, når de overvejer "build" -optionen, handler ikke kun om projektets bygnings- og udviklingsdele. Der er ofte en enorm indlæringskurve for endda at nå det punkt, hvor ægte AI / ML-udvikling kan forekomme. Med nye AI / ML-hold og initiativer opvejer antallet af "ukendte ukendte" langt antallet af "kendte ukendte".
| Byg | KØB |
|---|---|
Fordele:
| Fordele:
|
Ulemper:
| Ulemper:
|
For at gøre tingene endnu enklere skal du overveje følgende aspekter:
- når du arbejder på enorme datamængder
- når du arbejder på forskellige varianter af data
- når funktionaliteterne forbundet med dine modeller eller løsninger kan ændre sig eller udvikle sig i fremtiden
- når du har en vag eller generisk brugssag
- når du har brug for en klar idé om udgifterne ved implementering af et dataanmærkningsværktøj
- og når du ikke har den rette arbejdsstyrke eller dygtige eksperter til at arbejde på værktøjerne og leder efter en minimal læringskurve
Hvis dine svar var modsatte af disse scenarier, skal du fokusere på at opbygge dit værktøj.
Sådan vælger du det rigtige dataanmærkningsværktøj til dit projekt
Hvis du læser dette, lyder disse ideer spændende og er bestemt lettere sagt end gjort. Så hvordan går man i gang med at udnytte overfloden af allerede eksisterende værktøjer til datanotering derude? Så det næste trin involveret er at overveje de faktorer, der er forbundet med at vælge det rigtige data-annoteringsværktøj.
I modsætning til for få år siden har markedet udviklet sig med masser af dataanmærkningsværktøjer i praksis i dag. Virksomheder har flere muligheder for at vælge en baseret på deres forskellige behov. Men hvert enkelt værktøj leveres med sit eget sæt fordele og ulemper. For at tage en klog beslutning skal der også tages en objektiv rute bortset fra subjektive krav.
Lad os se på nogle af de afgørende faktorer, du skal overveje i processen.
Definition af din brugssag
For at vælge det rigtige data-annoteringsværktøj skal du definere din brugssag. Du bør indse, om dit krav involverer tekst, billede, video, lyd eller en blanding af alle datatyper. Der er enkeltstående værktøjer, du kan købe, og der er holistiske værktøjer, der giver dig mulighed for at udføre forskellige handlinger på datasæt.
Værktøjerne i dag er intuitive og tilbyder dig muligheder med hensyn til lagerfaciliteter (netværk, lokal eller cloud), annoteringsteknikker (lyd, billede, 3D og mere) og en række andre aspekter. Du kan vælge et værktøj baseret på dine specifikke krav.
Etablering af standarder for kvalitetskontrol
 Dette er en afgørende faktor at overveje, da formålet og effektiviteten med dine AI-modeller afhænger af de kvalitetsstandarder, du opretter. Ligesom en revision skal du udføre kvalitetskontrol af de data, du fodrer, og de opnåede resultater for at forstå, om dine modeller trænes på den rigtige måde og til de rigtige formål. Spørgsmålet er dog, hvordan agter du at etablere kvalitetsstandarder?
Dette er en afgørende faktor at overveje, da formålet og effektiviteten med dine AI-modeller afhænger af de kvalitetsstandarder, du opretter. Ligesom en revision skal du udføre kvalitetskontrol af de data, du fodrer, og de opnåede resultater for at forstå, om dine modeller trænes på den rigtige måde og til de rigtige formål. Spørgsmålet er dog, hvordan agter du at etablere kvalitetsstandarder?
Som med mange forskellige slags job kan mange mennesker foretage en datanotering og tagging, men de gør det med forskellige grader af succes. Når du beder om en tjeneste, verificerer du ikke automatisk niveauet for kvalitetskontrol. Derfor varierer resultaterne.
Så vil du implementere en konsensusmodel, hvor kommentatorer giver feedback om kvalitet, og korrigerende foranstaltninger træffes med det samme? Eller foretrækker du prøvevurdering, guldstandarder eller kryds frem for fagmodeller?
Den bedste købsplan vil sikre, at kvalitetskontrollen er på plads lige fra begyndelsen ved at sætte standarder, inden der er aftalt nogen endelig kontrakt. Når du opretter dette, bør du ikke overse fejlmargener også. Manuel indgriben kan ikke undgås fuldstændigt, da systemer sandsynligvis producerer fejl med op til 3%. Dette tager arbejde foran, men det er det værd.
Hvem vil kommentere dine data?
Den næste vigtige faktor er afhængig af, hvem der kommenterer dine data. Har du til hensigt at have et internt team, eller vil du hellere få det outsourcet? Hvis du outsourcer, er der legaliteter og overholdelsesforanstaltninger, du skal overveje på grund af de problemer, der vedrører fortrolighed og fortrolighed forbundet med data. Og hvis du har et internt team, hvor effektive er de til at lære et nyt værktøj? Hvad er din time-to-market med dit produkt eller din tjeneste? Har du de rigtige kvalitetsmålinger og hold til at godkende resultaterne?
The Vendor Vs. Partnerdebat
 Datanotering er en samarbejdsproces. Det involverer afhængigheder og indviklinger som interoperabilitet. Dette betyder, at visse teams altid arbejder sammen med hinanden, og et af holdene kan være din leverandør. Derfor er den leverandør eller partner, du vælger, lige så vigtigt som det værktøj, du bruger til datamærkning.
Datanotering er en samarbejdsproces. Det involverer afhængigheder og indviklinger som interoperabilitet. Dette betyder, at visse teams altid arbejder sammen med hinanden, og et af holdene kan være din leverandør. Derfor er den leverandør eller partner, du vælger, lige så vigtigt som det værktøj, du bruger til datamærkning.
Med denne faktor skal aspekter som evnen til at holde dine data og intentioner fortrolige, hensigten om at acceptere og arbejde med feedback, være proaktiv med hensyn til datarekvisitioner, fleksibilitet i operationer og mere, overvejes, før du håndhænder en sælger eller en partner . Vi har medtaget fleksibilitet, fordi kravene til datanotering ikke altid er lineære eller statiske. De kan ændre sig i fremtiden, når du skalerer din virksomhed yderligere. Hvis du i øjeblikket kun beskæftiger dig med tekstbaserede data, vil du muligvis kommentere lyd- eller videodata, mens du skalerer, og din support skal være klar til at udvide deres horisonter med dig.
Leverandørinddragelse
En af måderne til at vurdere leverandørinddragelse er den support, du får.
Enhver købsplan skal have en vis overvejelse af denne komponent. Hvordan vil støtte se ud på jorden? Hvem vil interessenterne og pege folk være på begge sider af ligningen?
Der er også konkrete opgaver, der skal præciseres, hvad leverandørens engagement er (eller vil være). Især for et datanotering eller datamærkningsprojekt, vil sælgeren aktivt levere rådataene eller ej? Hvem vil fungere som fageksperter, og hvem vil ansætte dem enten som ansatte eller uafhængige entreprenører?
Casestudier
Her er nogle specifikke casestudieeksempler, der omhandler, hvordan dataanmærkning og datamærkning virkelig fungerer på stedet. Hos Shaip sørger vi for at levere de højeste kvalitetsniveauer og overlegne resultater inden for datakommentarer og datamærkning.
Meget af ovenstående diskussion af standardpræstationer for dataanmærkning og datamærkning afslører, hvordan vi nærmer os hvert enkelt projekt, og hvad vi tilbyder til de virksomheder og interessenter, vi arbejder med.
Case -studiemateriale, der viser, hvordan dette fungerer:

I et klinisk datalicenseringsprojekt behandlede Shaip-teamet over 6,000 timers lyd, fjernede al beskyttet sundhedsinformation (PHI) og efterlod HIPAA-kompatibelt indhold til talegenkendelsesmodeller til sundhedsvæsenet at arbejde på.
I denne type tilfælde er det kriterierne og klassificeringen af resultater, der er vigtige. De rå data er i form af lyd, og der er behov for at identificere parter. For eksempel er brugen af NER-analyse det dobbelte mål at de-identificere og kommentere indholdet.
Et andet casestudie involverer en dybdegående samtale AI træningsdata projekt, som vi gennemførte med 3,000 lingvister, der arbejdede over en 14-ugers periode. Dette førte til produktion af træningsdata på 27 sprog for at udvikle flersprogede digitale assistenter, der er i stand til at håndtere menneskelige interaktioner på et bredt udvalg af modersmål.
I denne særlige casestudie var behovet for at få den rigtige person i den rigtige stol tydelig. Det store antal fageksperter og indholdsinputoperatører betød, at der var behov for organisering og proceduremæssig strømlining for at få projektet færdigt på en bestemt tidslinje. Vores team var i stand til at slå industristandarden med en bred margin ved at optimere dataindsamlingen og efterfølgende processer.
Andre typer casestudier involverer ting som bot-træning og tekstkommentar til maskinindlæring. Igen, i et tekstformat, er det stadig vigtigt at behandle identificerede parter i henhold til fortrolighedslove og at sortere gennem rådataene for at få de målrettede resultater.
Med andre ord, ved at arbejde på tværs af flere datatyper og -formater, har Shaip vist den samme vitale succes ved at anvende de samme metoder og principper til både rådata og datalicenser-forretningsscenarier.