

Hvad er store sprogmodeller?
Large Language Models (LLM'er) er avancerede kunstig intelligens (AI)-systemer designet til at behandle, forstå og generere menneskelignende tekst. De er baseret på deep learning-teknikker og trænet på massive datasæt, som normalt indeholder milliarder af ord fra forskellige kilder som websteder, bøger og artikler. Denne omfattende uddannelse gør det muligt for LLM'er at forstå nuancerne af sprog, grammatik, kontekst og endda nogle aspekter af generel viden.
Nogle populære LLM'er, som OpenAI's GPT-3, anvender en type neuralt netværk kaldet en transformer, som giver dem mulighed for at håndtere komplekse sprogopgaver med bemærkelsesværdig dygtighed. Disse modeller kan udføre en bred vifte af opgaver, såsom:
- Besvarelse af spørgsmål
- Opsummerende tekst
- Oversættelse af sprog
- Generering af indhold
- Selv engagere sig i interaktive samtaler med brugere
Efterhånden som LLM'er fortsætter med at udvikle sig, rummer de et stort potentiale for at forbedre og automatisere forskellige applikationer på tværs af brancher, fra kundeservice og indholdsskabelse til uddannelse og forskning. Men de rejser også etiske og samfundsmæssige bekymringer, såsom forudindtaget adfærd eller misbrug, som skal løses i takt med at teknologien udvikler sig.

Populære eksempler på store sprogmodeller
Her er et par fremtrædende eksempler på LLM'er, der anvendes bredt i forskellige brancher:
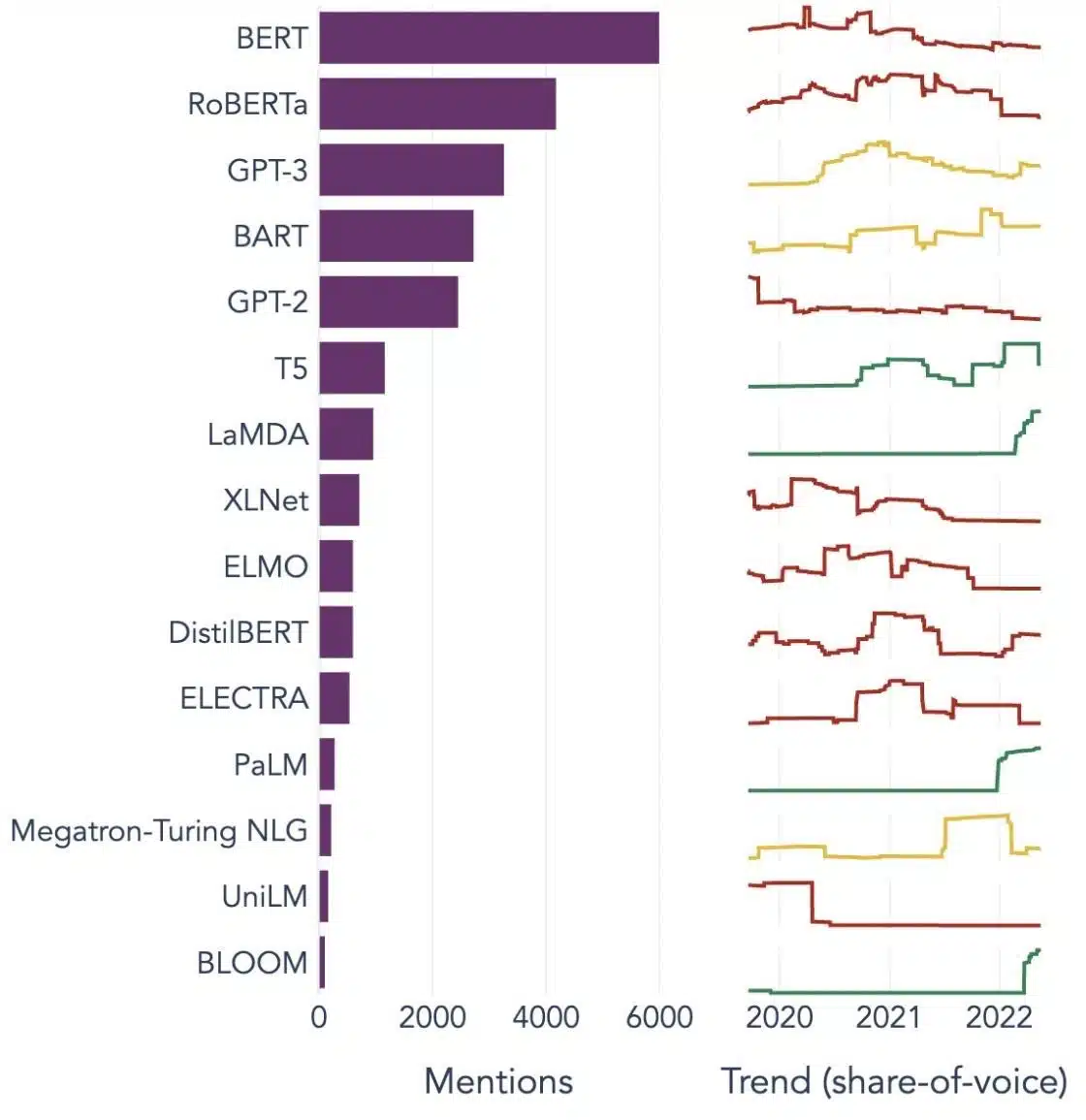
Billede Kilde: Mod datavidenskab
Hvordan trænes LLM-modeller?
At træne store sprogmodeller (LLM'er) er noget af en bedrift, der involverer flere afgørende trin. Her er en forenklet, trin-for-trin gennemgang af processen:
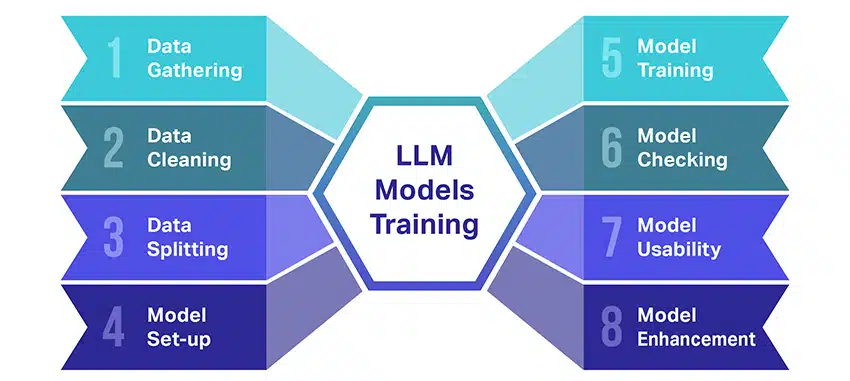
- Indsamling af tekstdata: Træning af en LLM starter med indsamlingen af en stor mængde tekstdata. Disse data kan komme fra bøger, websteder, artikler eller sociale medieplatforme. Målet er at fange den rige mangfoldighed af det menneskelige sprog.
- Oprydning af data: De rå tekstdata ryddes derefter op i en proces kaldet forbehandling. Dette inkluderer opgaver som at fjerne uønskede tegn, nedbryde teksten i mindre dele kaldet tokens og få det hele til et format, som modellen kan arbejde med.
- Opdeling af data: Dernæst opdeles de rene data i to sæt. Et sæt, træningsdataene, vil blive brugt til at træne modellen. Det andet sæt, valideringsdataene, vil senere blive brugt til at teste modellens ydeevne.
- Opsætning af modellen: Strukturen af LLM, kendt som arkitekturen, defineres derefter. Dette involverer valg af typen af neuralt netværk og beslutning om forskellige parametre, såsom antallet af lag og skjulte enheder i netværket.
- Træning af modellen: Den egentlige træning begynder nu. LLM-modellen lærer ved at se på træningsdataene, lave forudsigelser baseret på, hvad den har lært indtil nu, og derefter justere dens interne parametre for at reducere forskellen mellem dens forudsigelser og de faktiske data.
- Kontrol af modellen: LLM-modellens læring kontrolleres ved hjælp af valideringsdata. Dette hjælper med at se, hvor godt modellen klarer sig, og til at justere modellens indstillinger for bedre ydeevne.
- Brug af modellen: Efter træning og evaluering er LLM-modellen klar til brug. Det kan nu integreres i applikationer eller systemer, hvor det vil generere tekst baseret på nye input, det er givet.
- Forbedring af modellen: Endelig er der altid plads til forbedringer. LLM-modellen kan forfines yderligere over tid ved at bruge opdaterede data eller justere indstillinger baseret på feedback og brug i den virkelige verden.
Husk, at denne proces kræver betydelige beregningsressourcer, såsom kraftfulde behandlingsenheder og stort lager, samt specialiseret viden inden for maskinlæring. Det er derfor, det normalt udføres af dedikerede forskningsorganisationer eller virksomheder med adgang til den nødvendige infrastruktur og ekspertise.
Er LLM afhængig af overvåget eller uovervåget læring?
Store sprogmodeller trænes normalt ved hjælp af en metode kaldet supervised learning. Enkelt sagt betyder det, at de lærer af eksempler, der viser dem de rigtige svar.
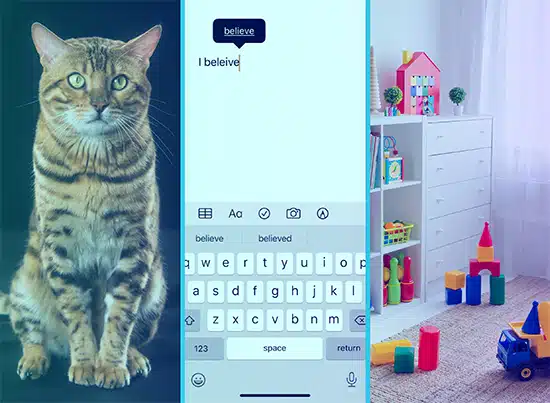 Forestil dig, at du lærer et barn ord ved at vise dem billeder. Du viser dem et billede af en kat og siger "kat", og de lærer at forbinde det billede med ordet. Sådan fungerer superviseret læring. Modellen får masser af tekst (“billederne”) og de tilsvarende output (“ordene”), og den lærer at matche dem.
Forestil dig, at du lærer et barn ord ved at vise dem billeder. Du viser dem et billede af en kat og siger "kat", og de lærer at forbinde det billede med ordet. Sådan fungerer superviseret læring. Modellen får masser af tekst (“billederne”) og de tilsvarende output (“ordene”), og den lærer at matche dem.
Så hvis du giver en LLM en sætning, forsøger den at forudsige det næste ord eller den næste sætning baseret på, hvad den har lært af eksemplerne. På denne måde lærer den, hvordan man genererer tekst, der giver mening og passer til konteksten.
Når det er sagt, bruger LLM'er nogle gange også lidt uovervåget læring. Det er som at lade barnet udforske et rum fyldt med forskelligt legetøj og lære om dem på egen hånd. Modellen ser på umærkede data, læringsmønstre og strukturer uden at få at vide de "rigtige" svar.
Overvåget læring anvender data, der er blevet mærket med input og output, i modsætning til uovervåget læring, som ikke bruger mærkede outputdata.
I en nøddeskal trænes LLM'er hovedsageligt ved hjælp af superviseret læring, men de kan også bruge uovervåget læring til at forbedre deres evner, såsom til udforskende analyse og dimensionalitetsreduktion.
Hvad er den datamængde (i GB), der er nødvendig for at træne en stor sprogmodel?
En verden af muligheder for taledatagenkendelse og stemmeapplikationer er enorm, og de bliver brugt i flere industrier til et væld af applikationer.
At træne en stor sprogmodel er ikke en ensartet proces, især når det kommer til de nødvendige data. Det afhænger af en masse ting:
- Modeldesignet.
- Hvilket arbejde skal det udføre?
- Den type data, du bruger.
- Hvor godt vil du have den til at fungere?
Når det er sagt, kræver træning af LLM'er normalt en enorm mængde tekstdata. Men hvor massivt taler vi om? Nå, tænk langt ud over gigabyte (GB). Vi ser normalt på terabyte (TB) eller endda petabyte (PB) data.
Overvej GPT-3, en af de største LLM'er, der findes. Det trænes på 570 GB tekstdata. Mindre LLM'er har måske brug for mindre – måske 10-20 GB eller endda 1 GB gigabyte – men det er stadig meget.

Men det handler ikke kun om størrelsen af dataene. Kvalitet betyder også noget. Dataene skal være rene og varierede for at hjælpe modellen med at lære effektivt. Og du kan ikke glemme andre nøglebrikker i puslespillet, såsom den computerkraft, du har brug for, de algoritmer, du bruger til træning, og den hardwareopsætning, du har. Alle disse faktorer spiller en stor rolle i træningen af en LLM.
Fremkomsten af store sprogmodeller: hvorfor de betyder noget
LLM'er er ikke længere kun et koncept eller et eksperiment. De spiller i stigende grad en afgørende rolle i vores digitale landskab. Men hvorfor sker det? Hvad gør disse LLM'er så vigtige? Lad os dykke ned i nogle nøglefaktorer.
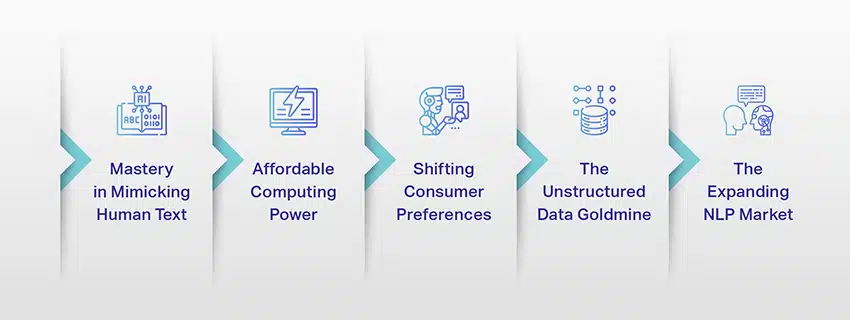
Beherskelse i at efterligne menneskelig tekst
LLM'er har transformeret den måde, vi håndterer sprogbaserede opgaver på. Disse modeller er bygget ved hjælp af robuste maskinlæringsalgoritmer og er udstyret med evnen til at forstå nuancerne i det menneskelige sprog, herunder kontekst, følelser og endda sarkasme, til en vis grad. Denne evne til at efterligne menneskeligt sprog er ikke blot en nyhed, den har betydelige implikationer.
LLM'ers avancerede tekstgenereringsevner kan forbedre alt fra oprettelse af indhold til kundeserviceinteraktioner.
Forestil dig at kunne stille en digital assistent et komplekst spørgsmål og få et svar, der ikke kun giver mening, men også er sammenhængende, relevant og leveret i en samtaletone. Det er, hvad LLM'er muliggør. De fremmer en mere intuitiv og engagerende interaktion mellem menneske og maskine, beriger brugeroplevelser og demokratiserer adgangen til information.
Overkommelig regnekraft
Fremkomsten af LLM'er ville ikke have været mulig uden en parallel udvikling inden for databehandling. Mere specifikt har demokratiseringen af beregningsressourcer spillet en væsentlig rolle i udviklingen og vedtagelsen af LLM'er.
Cloud-baserede platforme tilbyder hidtil uset adgang til højtydende computerressourcer. På denne måde kan selv små organisationer og uafhængige forskere træne sofistikerede maskinlæringsmodeller.
Desuden har forbedringer i behandlingsenheder (som GPU'er og TPU'er), kombineret med stigningen i distribueret databehandling, gjort det muligt at træne modeller med milliarder af parametre. Denne øgede tilgængelighed af computerkraft muliggør vækst og succes for LLM'er, hvilket fører til mere innovation og applikationer på området.
Skiftende forbrugerpræferencer
Forbrugerne i dag vil ikke kun have svar; de ønsker engagerende og relaterbare interaktioner. Efterhånden som flere mennesker vokser op med digital teknologi, er det tydeligt, at behovet for teknologi, der føles mere naturlig og menneskelignende, stiger. LLM'er tilbyder en uovertruffen mulighed for at opfylde disse forventninger. Ved at generere menneskelignende tekst kan disse modeller skabe engagerende og dynamiske digitale oplevelser, som kan øge brugernes tilfredshed og loyalitet. Uanset om det er AI-chatbots, der leverer kundeservice eller stemmeassistenter, der leverer nyhedsopdateringer, indleder LLM'er en æra med AI, der forstår os bedre.
Den ustrukturerede data guldmine
Ustrukturerede data, såsom e-mails, opslag på sociale medier og kundeanmeldelser, er en skattekiste af indsigt. Det anslås, at overstået 80 % af virksomhedens data er ustruktureret og vokser med en hastighed på 55 % Per år. Disse data er en guldgrube for virksomheder, hvis de udnyttes korrekt.
LLM'er kommer i spil her med deres evne til at behandle og give mening om sådanne data i stor skala. De kan håndtere opgaver som sentimentanalyse, tekstklassificering, informationsudtrækning og mere og giver derved værdifuld indsigt.
Uanset om det drejer sig om at identificere tendenser fra opslag på sociale medier eller at måle kundetilfredshed fra anmeldelser, hjælper LLM'er virksomheder med at navigere i den store mængde ustrukturerede data og træffe datadrevne beslutninger.
Det ekspanderende NLP-marked
LLM'ernes potentiale afspejles i det hurtigt voksende marked for naturlig sprogbehandling (NLP). Analytikere forventer, at NLP-markedet kan udvides fra $11 milliarder i 2020 til over $35 milliarder i 2026. Men det er ikke kun markedsstørrelsen, der vokser. Selve modellerne vokser også, både i fysisk størrelse og i antallet af parametre, de håndterer. Udviklingen af LLM'er gennem årene, som det ses i figuren nedenfor (billedkilde: link), understreger deres stigende kompleksitet og kapacitet.
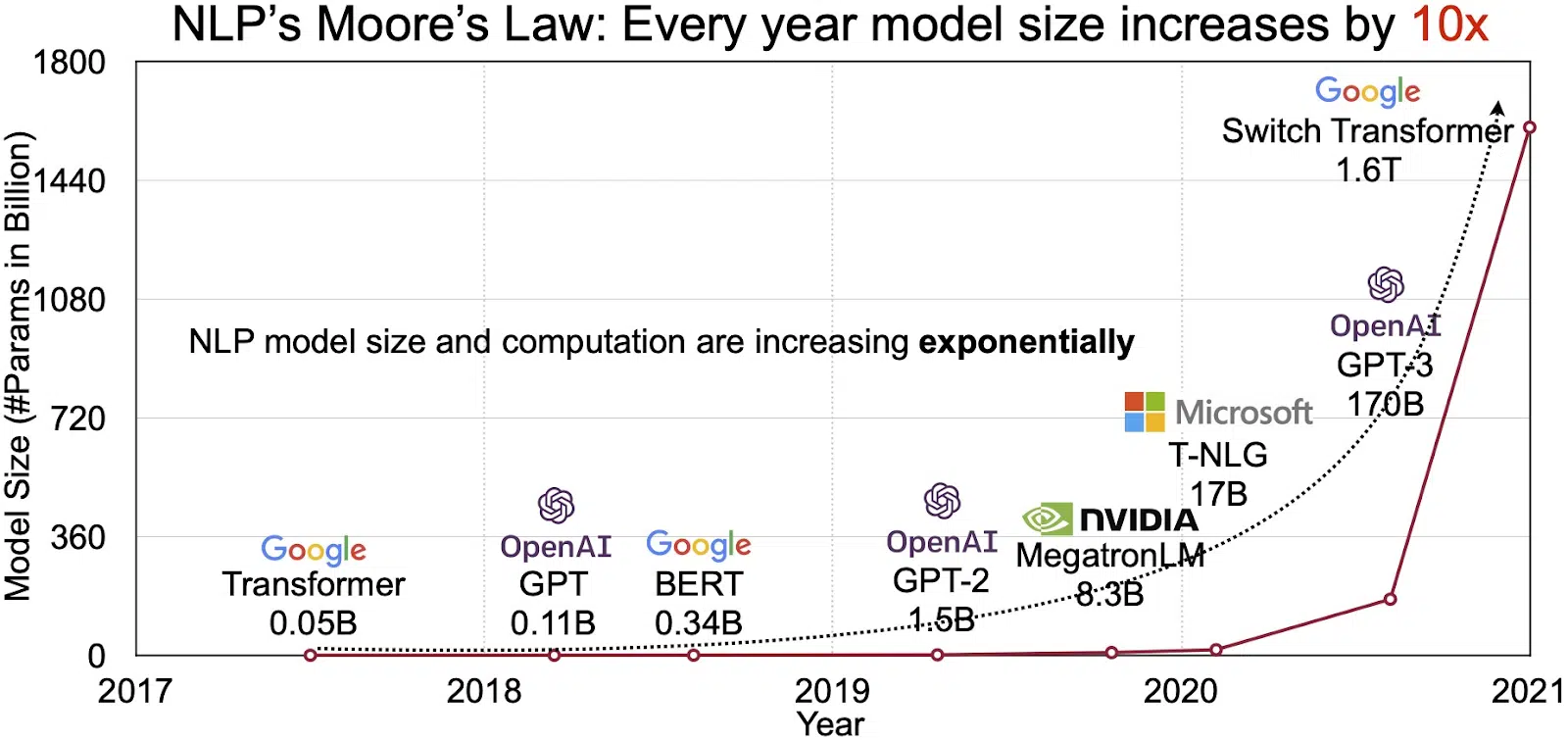
Populære eksempler på store sprogmodeller
Her er nogle af de bedste og mest udbredte brugssager af LLM:
- Generering af naturligt sprogtekst: Store sprogmodeller (LLM'er) kombinerer kraften fra kunstig intelligens og computerlingvistik til selvstændigt at producere tekster i naturligt sprog. De kan imødekomme forskellige brugerbehov, såsom at skrive artikler, lave sange eller deltage i samtaler med brugere.
- Oversættelse gennem maskiner: LLM'er kan effektivt bruges til at oversætte tekst mellem ethvert par sprog. Disse modeller udnytter dybe læringsalgoritmer som tilbagevendende neurale netværk til at forstå den sproglige struktur af både kilde- og målsprog, og derved lette oversættelsen af kildeteksten til det ønskede sprog.
- Udarbejdelse af originalt indhold: LLM'er har åbnet muligheder for maskiner til at generere sammenhængende og logisk indhold. Dette indhold kan bruges til at oprette blogindlæg, artikler og andre typer indhold. Modellerne udnytter deres dybe dybdelæringsoplevelse for at formatere og strukturere indholdet på en ny og brugervenlig måde.
- Analyse af følelser: En spændende anvendelse af store sprogmodeller er sentimentanalyse. Heri trænes modellen til at genkende og kategorisere følelsesmæssige tilstande og følelser, der er til stede i den kommenterede tekst. Softwaren kan identificere følelser som positivitet, negativitet, neutralitet og andre indviklede følelser. Dette kan give værdifuld indsigt i kundefeedback og synspunkter om forskellige produkter og tjenester.
- Forståelse, opsummering og klassificering af tekst: LLM'er etablerer en levedygtig struktur for AI-software til at fortolke teksten og dens kontekst. Ved at instruere modellen i at forstå og granske enorme mængder data, gør LLM'er det muligt for AI-modeller at forstå, opsummere og endda kategorisere tekst i forskellige former og mønstre.
- Besvarelse af spørgsmål: Store sprogmodeller udstyrer QA-systemer (Question Answering) med evnen til præcist at opfatte og svare på en brugers naturlige sprogforespørgsel. Populære eksempler på denne brugssag omfatter ChatGPT og BERT, som undersøger konteksten af en forespørgsel og gennemgår en stor samling af tekster for at levere relevante svar på brugerspørgsmål.

Part-of-Speech (POS)-mærkning
Ord i sætninger er mærket med deres grammatiske funktion, såsom verber, substantiver, adjektiver osv. Denne proces hjælper modellen med at forstå grammatikken og sammenhængene mellem ord.

Navngivet enhedsgenkendelse (NER)
Navngivne enheder som organisationer, lokationer og personer i en sætning er markeret. Denne øvelse hjælper modellen med at fortolke den semantiske betydning af ord og sætninger og giver mere præcise svar.

Følelsesanalyse
Tekstdata tildeles følelsesmærker som positiv, neutral eller negativ, hvilket hjælper modellen med at forstå den følelsesmæssige undertone af sætninger. Det er især nyttigt til at svare på forespørgsler, der involverer følelser og meninger.
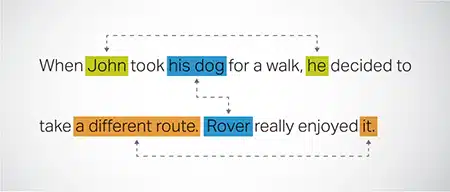
Coreference Opløsning
Identifikation og løsning af tilfælde, hvor der henvises til den samme enhed i forskellige dele af en tekst. Dette trin hjælper modellen med at forstå konteksten af sætningen, hvilket fører til sammenhængende svar.
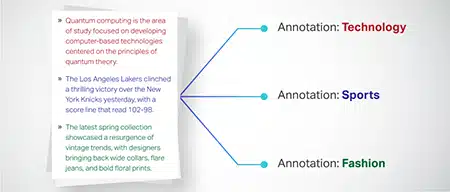
Tekstklassificering
Tekstdata er kategoriseret i foruddefinerede grupper som produktanmeldelser eller nyhedsartikler. Dette hjælper modellen med at skelne genren eller emnet for teksten og genererer mere relevante svar.
Shaips tilbud
Saip tilbyder en bred vifte af tjenester til at hjælpe organisationer med at administrere, analysere og få mest muligt ud af deres data.
Data web-skrabning
En nøgletjeneste, som Shaip tilbyder, er dataskrabning. Dette involverer udtræk af data fra domænespecifikke URL'er. Ved at bruge automatiserede værktøjer og teknikker kan Shaip hurtigt og effektivt skrabe store mængder data fra forskellige websteder, produktmanualer, teknisk dokumentation, onlinefora, onlineanmeldelser, kundeservicedata, brancheregulerende dokumenter osv. Denne proces kan være uvurderlig for virksomheder, når indsamling af relevante og specifikke data fra en lang række kilder.

Maskinoversættelse
Udvikle modeller ved hjælp af omfattende flersprogede datasæt parret med tilsvarende transskriptioner til oversættelse af tekst på tværs af forskellige sprog. Denne proces hjælper med at fjerne sproglige forhindringer og fremmer tilgængeligheden af information.
Taksonomi udvinding og skabelse
Shaip kan hjælpe med taksonomiudtrækning og oprettelse. Dette involverer klassificering og kategorisering af data i et struktureret format, der afspejler forholdet mellem forskellige datapunkter. Dette kan være særligt nyttigt for virksomheder til at organisere deres data, hvilket gør det mere tilgængeligt og lettere at analysere. For eksempel i en e-handelsvirksomhed kan produktdata kategoriseres baseret på produkttype, mærke, pris osv., hvilket gør det nemmere for kunderne at navigere i produktkataloget.
Dataindsamling
Vores dataindsamlingstjenester leverer kritiske virkelige eller syntetiske data, der er nødvendige for at træne generative AI-algoritmer og forbedre nøjagtigheden og effektiviteten af dine modeller. Dataene er upartiske, etisk og ansvarligt fremskaffet, samtidig med at der tages hensyn til databeskyttelse og sikkerhed.

Spørgsmål & svar
Spørgsmålsbesvarelse (QA) er et underområde af naturlig sprogbehandling, der fokuserer på automatisk besvarelse af spørgsmål på menneskeligt sprog. QA-systemer er trænet i omfattende tekst og kode, hvilket gør dem i stand til at håndtere forskellige typer spørgsmål, herunder faktuelle, definitionsmæssige og meningsbaserede. Domæneviden er afgørende for at udvikle QA-modeller, der er skræddersyet til specifikke områder som kundesupport, sundhedspleje eller forsyningskæde. Generative QA-tilgange tillader imidlertid modeller at generere tekst uden domæneviden, udelukkende baseret på kontekst.
Vores team af specialister kan omhyggeligt studere omfattende dokumenter eller manualer for at generere spørgsmål-svar-par, hvilket letter skabelsen af Generativ AI for virksomheder. Denne tilgang kan effektivt tackle brugerforespørgsler ved at hente relevant information fra et omfattende korpus. Vores certificerede eksperter sikrer produktionen af topkvalitets Q&A-par, der spænder over forskellige emner og domæner.

Tekstopsummering
Vores specialister er i stand til at destillere omfattende samtaler eller lange dialoger og levere kortfattede og indsigtsfulde resuméer fra omfattende tekstdata.

Tekstgenerering
Træn modeller ved hjælp af et bredt datasæt af tekst i forskellige stilarter, såsom nyhedsartikler, fiktion og poesi. Disse modeller kan derefter generere forskellige typer indhold, herunder nyheder, blogindlæg eller indlæg på sociale medier, hvilket tilbyder en omkostningseffektiv og tidsbesparende løsning til oprettelse af indhold.
Talegenkendelse
Udvikle modeller, der er i stand til at forstå talt sprog til forskellige applikationer. Dette inkluderer stemmeaktiverede assistenter, dikteringssoftware og realtidsoversættelsesværktøjer. Processen involverer anvendelse af et omfattende datasæt bestående af lydoptagelser af talt sprog, parret med deres tilsvarende transskriptioner.

Produktanbefalinger
Udvikl modeller ved hjælp af omfattende datasæt af kundekøbshistorier, herunder etiketter, der påpeger de produkter, kunder er tilbøjelige til at købe. Målet er at give præcise forslag til kunderne og derved øge salget og øge kundetilfredsheden.
Billedtekst
Revolutioner din billedfortolkningsproces med vores state-of-the-art, AI-drevet billedteksttjeneste. Vi tilfører billeder vitalitet ved at producere nøjagtige og kontekstuelt meningsfulde beskrivelser. Dette baner vejen for innovative engagement og interaktionsmuligheder med dit visuelle indhold til dit publikum.

Træning af tekst-til-tale-tjenester
Vi leverer et omfattende datasæt bestående af lydoptagelser af menneskelig tale, ideel til træning af AI-modeller. Disse modeller er i stand til at generere naturlige og engagerende stemmer til dine applikationer og dermed levere en markant og fordybende lydoplevelse for dine brugere.



