
Fordele ved OCR
Optisk tegngenkendelse – OCR-teknologi – bringer en række fordele, hvoraf nogle er:
Øg hastigheden af processen:
Ved hurtigt at konvertere ustrukturerede data til maskinlæsbar og søgbar information hjælper teknologien med at øge hastigheden af forretningsprocesser.
Øger nøjagtigheden:
Risikoen for menneskelige fejl er elimineret, hvilket forbedrer den overordnede nøjagtighed af karaktergenkendelsen.
Reducerer behandlingsomkostninger:
Softwaren til optisk tegngenkendelse er ikke helt afhængig af andre teknologier, hvilket reducerer behandlingsomkostningerne.
Forbedrer produktiviteten:
Da information er let tilgængelig og søgbar, har medarbejderne mere tid til at udføre produktive opgaver og nå mål.
Forbedrer kundetilfredsheden:
Tilgængeligheden af information i et let søgbart format sikrer højere tilfredshedsniveauer og en bedre kundeoplevelse.
Brugscases og applikationer
Bevaring af dokumenter / Digitalisering af dokumenter
 Gamle historiske dokumenter af værdi kan bevares, opbevares og gøres uforgængelige ved at konvertere dem til digitaliseret format. OCR-teknologi bliver brugt til at digitalisere antikke og sjældne bøger, så disse manuskripter med uregelmæssige skrifttyper kan ændres digitalt og gøres søgbare for fremtiden.
Gamle historiske dokumenter af værdi kan bevares, opbevares og gøres uforgængelige ved at konvertere dem til digitaliseret format. OCR-teknologi bliver brugt til at digitalisere antikke og sjældne bøger, så disse manuskripter med uregelmæssige skrifttyper kan ændres digitalt og gøres søgbare for fremtiden.
Bank og finans
Bank- og finanssektoren bruger OLT-teknologien til sit hjerte. Denne teknologi hjælper med at forbedre forebyggelsen af sikkerhedssvig, reducere risikoen og hurtigere behandling. Banker og bankapps bruger OCR til at udtrække vigtige data fra checks såsom kontonummer, beløb og håndsignatur. OCR hjælper med hurtigere behandling af låne- og realkreditansøgninger, fakturaer og lønsedler.
Før OCR blev mere almindeligt, var alle bankdokumenter såsom optegnelser, kvitteringer, kontoudtog og checks fysiske. Med OCR-digitalisering kan banker og finansielle institutioner strømline processer, eliminere manuelle fejl og forbedre proceseffektiviteten ved hurtigt at få adgang til data.
Nummerpladegenkendelse
 OCR-teknologien bruges i vid udstrækning til at identificere numre og tekst på nummerplader. Denne teknologi bliver brugt til at identificere mistede biler, beregninger af parkeringsafgifter og forebyggelse af køretøjsforbrydelser.
OCR-teknologien bruges i vid udstrækning til at identificere numre og tekst på nummerplader. Denne teknologi bliver brugt til at identificere mistede biler, beregninger af parkeringsafgifter og forebyggelse af køretøjsforbrydelser.
OCR-teknologi hjælper med at implementere trafiksikkerhedsregler for at undgå svindel og kriminalitet. Da nummerpladerne på et køretøj er knyttet til førerens legitimationsoplysninger, er identifikation lettere.
Desuden består nummerpladerne af en velskrevet bunke tal og tekst, som ikke er svære at læse for AI-modellen, hvilket gør det nemmere og mere præcist.
Tekst-til-tale
Tekst-til-tale-anvendelse af OCR-teknologi er en fremragende hjælp for visuelt udfordrede mennesker til at fungere med større lethed. OCR-teknologi hjælper med at scanne fysiske og digitale tekster og bruge stemmeenheder. Indholdet læses derefter højt. Selvom tekst-til-tale-aspektet af OCR-teknologi har været en af de første applikationer, er den nu udviklet og avanceret for at imødekomme de unikke behov hos visuelt udfordrede mennesker ved at understøtte flere dialekter og sprog.
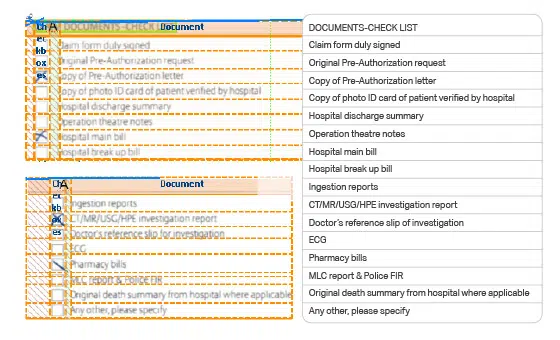
Transskription af multi-kategori Scannede papirdokumenter datasæt
 Ved hjælp af OCR-teknologi transskriberes fakturaer, kvitteringer, regninger og andre dokumenter af forskellige kategorier også effektivt. Nyhedsbreve, papirer med tal i cirkler, afkrydsningsboksformularer og dokumenter med flere kategorier såsom skatteformularer og manualer kan også digitaliseres.
Ved hjælp af OCR-teknologi transskriberes fakturaer, kvitteringer, regninger og andre dokumenter af forskellige kategorier også effektivt. Nyhedsbreve, papirer med tal i cirkler, afkrydsningsboksformularer og dokumenter med flere kategorier såsom skatteformularer og manualer kan også digitaliseres.
Transskriber medicinske etiketter med OCR
 Ved at hjælpe med at scanne receptpligtige medicinske etiketter ved hjælp af OCR, er det nu muligt automatisk at fange medicinske data. Det medicinske data er fanget fra håndskrevne recepter, lægemiddeloplysninger og mængde for at undgå manuelle fejl, overlapninger og uagtsomhed.
Ved at hjælpe med at scanne receptpligtige medicinske etiketter ved hjælp af OCR, er det nu muligt automatisk at fange medicinske data. Det medicinske data er fanget fra håndskrevne recepter, lægemiddeloplysninger og mængde for at undgå manuelle fejl, overlapninger og uagtsomhed.
Med OCR kan sundhedsindustrien hurtigt scanne, gemme og søge efter en patients sygehistorie. OCR'en gør det muligt at digitalisere og opbevare scanningsrapporter, behandlingshistorik, hospitalsjournaler, forsikringsjournaler, røntgenbilleder og andre dokumenter. Ved at digitalisere, transskribere og opbevare medicinske etiketter gør OCR det nemt at strømline procesflowet og fremskynde sundhedsvæsenet.
Detektering af Gade/Vej & Udtræk Information Street Board-data med OCR
 Automatisk detektering, identifikation og klassificering af vej-/gadeskilte udføres med OCR. Ved at registrere vejskilte leder OCR chaufførerne mod en mere sikker rejse. OCR-teknologien fungerer lige så godt under dårlige lysforhold, registrerer vejskilte på flere sprog og forskelligt formede skilte og klassificerer det samme for fremtiden.
Automatisk detektering, identifikation og klassificering af vej-/gadeskilte udføres med OCR. Ved at registrere vejskilte leder OCR chaufførerne mod en mere sikker rejse. OCR-teknologien fungerer lige så godt under dårlige lysforhold, registrerer vejskilte på flere sprog og forskelligt formede skilte og klassificerer det samme for fremtiden.
At udvikle en intelligent karaktergenkendelse værktøj, skal du træne det med det projektspecifikke datasæt.
Hos Shaip leverer vi et fuldstændigt tilpasset dokumentdatasæt til at udvikle meget funktionelt OCR til AI- og ML-modeller. Vores specialiserede processen med OCR hjælper med at udvikle optimerede løsninger til kunder.
Vi leverer omfattende og pålidelige datasæt, der indeholder tusindvis af forskellige udtrukne data fra scannede dokumenter. Kom i kontakt med vores OCR løsninger eksperter til at vide, hvordan vi leverer skalerbare, overkommelige og kundespecifikke datasæt.


