







Tekstindsamling

Samling af lyd/tale
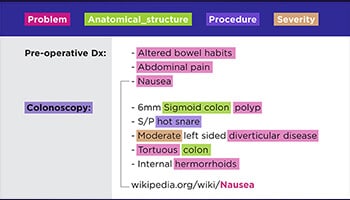
Tekstkommentar
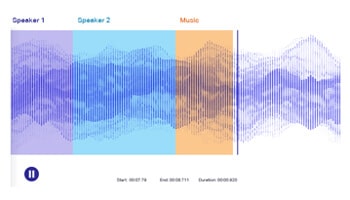
Lyd / tale annotering

Teksttranskription

Lyd / tale transskription


Samtale AI / Chatbot-træning
Uddannelse af digitale assistenter kræver et stort sæt kvalitetsdata fra forskellige geografier, sprog, dialekter, opsætninger og formater. Hos Shaip tilbyder vi træningsdata til AI-modeller med Human-in-the-loop, der har den nødvendige viden, domæneekspertise og er godt klar over kundens specifikke behov.
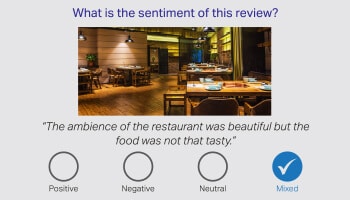
Følelse / hensigt
Analyse
Det siges med rette, at ord alene ikke formidler hele historien, og ansvaret ligger på menneskelige annotatorer for at fortolke tvetydigheden på menneskeligt sprog. Derfor er det yderst vigtigt at identificere en kundes følelse baseret på samtalen. Vores sprogeksperter fra forskellige domæner kan fortolke nuancer i produktanmeldelser, finansielle nyheder og sociale medier.

Navngivet enhedsgenkendelse (NER)
Named Entity Recognition (NER) er at identificere, udtrække og klassificere de navngivne enheder i en tekst i foruddefinerede kategorier. Teksten kan kategoriseres som et sted, navn, organisation, produkt, mængde, værdi, procentdel osv. Med NER kan du tage fat på virkelige spørgsmål som f.eks. Hvilke organisationer der blev nævnt i artiklen osv.
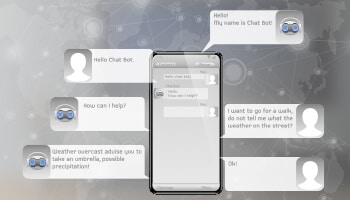
Automatisering af kundeservice
Robuste, veluddannede virtuelle chatbots eller digitale assistenter har revolutioneret den måde, hvorpå kunder kommunikerer med sælgere, hvilket bidrager til en væsentlig forbedring af kundeoplevelsen.

Teksttranskription
Fra læger håndskrevne recepter til konferenceopkaldsnotater, vores specialister kan digitalisere enhver form for data, dvs. arkiverede dokumenter, juridiske kontrakter, patienttjournaler osv.

Indholdskategorisering
Kategorisering også kendt som klassificering eller tagging er processen med at klassificere tekst i organiserede grupper og mærke den, baseret på dens interessefunktioner.

Emneanalyse
Emneanalyse eller emnemærkning er at identificere og udtrække mening fra en given tekst ved at identificere tilbagevendende emner / temaer, der overvejes.

Lydtranskription
Transkriber tale/podcast/seminar, kald samtale til tekst. Udnyt mennesker til nøjagtigt at kommentere lyd-/talefiler for at træne NLP -modeller præcist.

Audio Klassificering
Kategoriser lyde eller udtalelser for at klassificere tale / lyd baseret på sprog, dialekt, semantik, leksikoner osv.

Mennesker
Dedikerede og uddannede hold:
- 30,000+ samarbejdspartnere til oprettelse af data, mærkning og kvalitetssikring
- Godkendt projektledelsesteam
- Erfaren produktudviklingsteam
- Talent Pool Sourcing & Onboarding Team

Proces
Højeste proceseffektivitet sikres med:
- Robust 6 Sigma Stage-Gate-proces
- Et dedikeret team med 6 Sigma-sorte bælter - Nøgleprocessejere og overholdelse af kvalitet
- Løbende forbedring og feedback

perron
Den patenterede platform giver fordele:
- Web-baseret ende-til-ende platform
- Upåklagelig kvalitet
- Hurtigere TAT
- Problemfri levering


