I de senere år har kunstig intelligens (AI) gjort betydelige fremskridt i forskellige brancher, og sundhedsvæsenet er ingen undtagelse. Generativ AI, en undergruppe af AI, der fokuserer på at skabe nyt indhold baseret på eksisterende data, revolutionerer den måde, sundhedspersonale griber diagnose og behandling på. Shaip, en førende leverandør af AI-løsninger, er på forkant med denne transformation og tilbyder avancerede medicinske datasæt, der giver næring til generative AI-applikationer i sundhedssektoren.
Shaips mission er at levere omfattende datarammer, der muliggør præcise, hurtige og banebrydende AI-drevne diagnoser og behandlinger. Med en dyb forståelse af de unikke krav til medicinsk AI tilbyder Shaip et omfattende udvalg af datasæt designet til at drive generative AI-applikationer i sundhedssektoren.
1. Spørgsmål & svar-par
Et af nøgleområderne, hvor Shaips generative AI-løsninger udmærker sig, er at besvare spørgsmål. Ved at kurere spørgsmål-svar-par fra sundhedsdokumenter og litteratur, letter Shaips certificerede fagfolk udviklingen af AI-modeller, der kan foreslå diagnostiske procedurer, anbefale behandlinger og hjælpe læger med at give indsigt ved at filtrere relevant information. Denne teknologi har potentialet til at strømline den diagnostiske proces, reducere fejl og forbedre patientresultaterne.

Vores sundhedsspecialister producerer top-tier Q&A-sæt, som omfatter:
- Oprettelse af forespørgsler på overfladeniveau
- Design af spørgsmål på dybt niveau
- Indramning af spørgsmål og svar fra medicinske tabeldata
Spørgsmål og svar-sættene er oprettet ved hjælp af forskellige kilder, såsom:
- Kliniske retningslinjer og protokoller
- Patient-udbyder interaktionsdata
- Medicinske forskningsartikler
- Farmaceutisk produktinformation
- Sundhedsregulative dokumenter
- Patientudtalelser, anmeldelser, fora og fællesskaber
2. Tekstopsummering
Et andet afgørende aspekt af Shaips generative AI-tilbud er tekstresumé. Sundhedspersonale står ofte over for udfordringen med at gennemsøge enorme mængder information, såsom elektroniske sundhedsjournaler (EPJ'er), forskningsartikler og læge-patient-samtaler. Shaips sundhedsspecialister udmærker sig ved at destillere denne information til klare og præcise opsummeringer, hvilket sikrer, at fagfolk hurtigt kan forstå kerneindsigter uden at skulle bruge timer på at læse lange dokumenter.

Vores tilbud omfatter:
Tekstbaseret EPJ opsummering: Indkapsl patientens sygehistorie, behandlinger og resultater i et let fordøjeligt format, der gør det muligt for sundhedsudbydere hurtigt at gennemgå og forstå en patients komplette medicinske rejse.
Læge-patient samtale opsummering: Uddrag nøglepunkter, bekymringer og handlingspunkter fra lægekonsultationer for at sikre, at kritisk information ikke overses, og faciliterer bedre kommunikation mellem sundhedsudbydere og patienter.
PDF-baseret forskningsartikel resumé: Destiller komplekse medicinske forskningsartikler ind i deres grundlæggende resultater, konklusioner og kliniske implikationer, så sundhedspersonale kan holde sig ajour med den seneste udvikling inden for deres felt uden at bruge for meget tid på litteraturgennemgange.
Sammenfatning af medicinsk billeddiagnostik: Konverter komplicerede røntgen- eller billeddiagnostiske rapporter til forenklede opsummeringer, der fremhæver de mest betydningsfulde resultater og anbefalinger, hvilket gør det muligt for sundhedsteams at træffe informerede beslutninger mere effektivt.
Opsummering af data fra kliniske forsøg: Neddel omfattende kliniske forsøgsresultater i de mest afgørende takeaways, herunder effektivitet, sikkerhed og potentielle anvendelser, hvilket giver sundhedsinteressenter mulighed for hurtigt at evaluere virkningen af nye behandlinger eller interventioner.
Ved at udnytte Shaips tekstresuméekspertise kan sundhedsorganisationer strømline deres informationsbehandling, forbedre beslutningstagningen og i sidste ende forbedre patientbehandlingen. Vores sundhedsspecialister er dedikerede til at levere præcise og relevante resuméer af høj kvalitet, der imødekommer sundhedsindustriens unikke behov.
3. Syntetisk dataoprettelse
Udover at besvare spørgsmål og tekstresumé, fokuserer Shaip også på oprettelse af syntetiske data. Syntetiske data er kritiske i sundhedsområdet til forskellige formål, såsom AI-modeltræning og softwaretest, uden at kompromittere patientens privatliv. Shaip tilbyder tjenester til oprettelse af syntetiske data til historie om nuværende sygdom (HPI) og fremskridtsnotater, EPJ-notater og læge-patient-samtalesammendrag på tværs af forskellige medicinske specialer.
3.1 Syntetiske data Oprettelse af HPI og fremskridtsnoter
Generering af kunstige, men realistiske, patientdata, der efterligner formatet og indholdet af en patients historie med nuværende sygdom (HPI) og fremskridtsnotater. Disse syntetiske data er værdifulde til træning af ML-algoritmer, test af sundhedssoftware og udførelse af forskning uden at risikere patientens privatliv.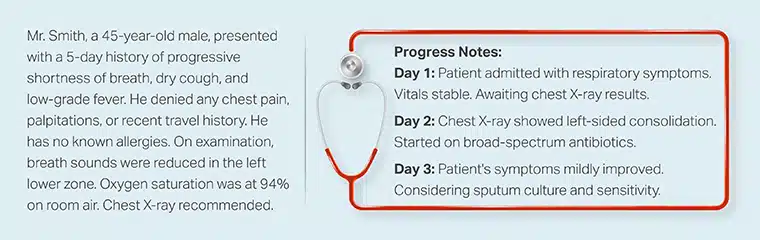
3.2 Syntetiske data Oprettelse af EPJ-noter
Denne proces indebærer oprettelse af simulerede elektroniske sundhedsjournaler (EPJ), der strukturelt og kontekstuelt ligner rigtige EPJ-notater. Disse syntetiske noter kan bruges til at træne sundhedspersonale, validere EPJ-systemer og udvikle AI-algoritmer til opgaver såsom prædiktiv modellering eller naturlig sprogbehandling, alt imens patientens fortrolighed bevares.

3.3 Syntetisk læge-patient samtale opsummering i forskellige domæner
Dette involverer generering af opsummerede versioner af simulerede læge-patient-interaktioner på tværs af forskellige medicinske specialer, såsom kardiologi eller dermatologi. Disse resuméer, selvom de er baseret på fiktive scenarier, ligner rigtige samtaleresuméer og kan bruges til medicinsk uddannelse, AI-træning og softwaretest uden at afsløre egentlige patientsamtaler eller kompromittere privatlivets fred.

Konklusion
Shaips generative AI-løsninger er drevet af omfattende og forskelligartede datasæt, strenge kvalitetssikringsprocedurer og en forpligtelse til datasikkerhed og privatliv. Virksomheden overholder GDPR- og HIPAA-reglerne, hvilket sikrer beskyttelsen af følsomme patientoplysninger.
Fordelene ved Shaips generative AI-løsninger i sundhedssektoren er talrige. Ved at udnytte disse teknologier kan sundhedspersonale forbedre nøjagtigheden af diagnoser, spare tid og penge på dataindsamling, fremskynde time-to-market for nye behandlinger og opnå en konkurrencefordel i branchen.
Efterhånden som sundhedsvæsenet fortsætter med at udvikle sig, vil generativ kunstig intelligens spille en stadig vigtigere rolle i at forme fremtiden for diagnose og behandling. Shaip er på forkant med denne transformation og giver sundhedspersonale de værktøjer og datasæt, de har brug for, for at levere mere nøjagtig, personlig og effektiv pleje til patienter over hele verden.