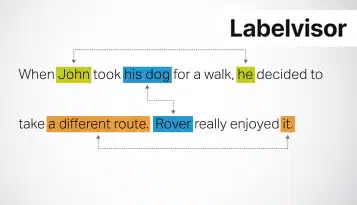
Navngivet enhedsgenkendelse (NER) er et nøgleaspekt af naturlig sprogbehandling (NLP), der hjælper med at identificere og kategorisere specifikke detaljer i store mængder tekst. NER-applikationer omfatter blandt andet informationsudtrækning, tekstresumé og sentimentanalyse. For effektiv NER er forskellige datasæt nødvendige for at træne maskinlæringsmodeller.
Fem vigtige open source-datasæt til NER er:
- CONLL 2003: Nyhedsdomæne
- CADEC: Medicinsk domæne
- WikiNEuRal: Wikipedia domæne
- OntoNotes 5: Forskellige domæner
- BBN: Forskellige domæner
Fordelene ved disse datasæt omfatter:
- Tilgængelighed: De er gratis og tilskynder til samarbejde
- Datarigdom: De indeholder forskellige data, hvilket forbedrer modellens ydeevne
- Fællesskabsstøtte: De kommer ofte med et støttende brugerfællesskab
- Facilitere forskning: Især nyttig for forskere med begrænsede dataindsamlingsressourcer
Men de kommer også med ulemper:
- Datakvalitet: De kan indeholde fejl eller skævheder
- Mangel på specificitet: De er muligvis ikke egnede til opgaver, der kræver specifikke data
- Bekymringer om sikkerhed og privatliv: Risici forbundet med følsomme oplysninger
- Vedligeholdelse: De modtager muligvis ikke regelmæssige opdateringer
På trods af de potentielle ulemper spiller open source-datasæt en væsentlig rolle i udviklingen af NLP og maskinlæring, specifikt inden for området for navngivne enhedsgenkendelse.
Læs hele artiklen her:
https://wikicatch.com/open-datasets-for-named-entity-recognition/