
Kunstig intelligens revolutionerer musikindustrien og tilbyder automatiserede værktøjer til komposition, mastering og performance. AI-algoritmer genererer nye kompositioner, forudsiger hits og tilpasser lytteroplevelsen og transformerer musikproduktion, distribution og forbrug. Denne nye teknologi byder på både spændende muligheder og udfordrende etiske dilemmaer.
Maskinlæringsmodeller (ML) kræver træningsdata for at fungere effektivt, da en komponist har brug for musikalske noder for at skrive en symfoni. I musikverdenen, hvor melodi, rytme og følelser fletter sig sammen, kan vigtigheden af kvalitetstræningsdata ikke overvurderes. Det er rygraden i at udvikle robuste og nøjagtige musik-ML-modeller til forudsigelig analyse, genreklassificering eller automatisk transskription.
Data, livsnerven i ML-modeller
Maskinlæring er i sagens natur datadrevet. Disse beregningsmodeller lærer mønstre fra dataene, hvilket gør dem i stand til at foretage forudsigelser eller beslutninger. For musik ML-modeller kommer træningsdata ofte i digitaliserede musiknumre, tekster, metadata eller en kombination af disse elementer. Disse datas kvalitet, kvantitet og mangfoldighed påvirker i høj grad modellens effektivitet.

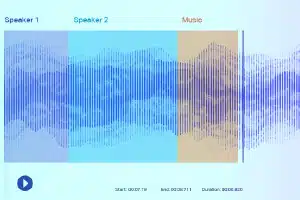
Lydmærkning
Med lydmærkning får dataannotatorerne en optagelse og skal adskille alle de nødvendige lyde og mærke dem. Det kan for eksempel være bestemte nøgleord eller lyden af et specifikt musikinstrument.

Klassifikation af musik
Dataannotatorer kan markere genrer eller instrumenter i denne form for lydannotering. Musikklassificering er meget nyttig til at organisere musikbiblioteker og forbedre brugeranbefalinger.

Fonetisk niveausegmentering
Mærkning og klassificering af fonetiske segmenter på bølgeformer og spektrogrammer af optagelser af individer, der synger acapella.
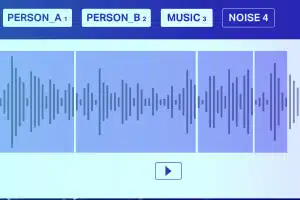
Lydklassificering
Bortset fra stilhed/hvid støj, består en lydfil typisk af følgende lydtyper Tale, Babble, Musik og Støj. Annotér musikalske noder nøjagtigt for højere nøjagtighed.
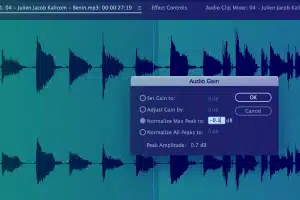
Opsamling af metadataoplysninger
Indfang vigtige oplysninger såsom starttid, sluttid, segment-id, lydstyrkeniveau, primær lydtype, sprogkode, højttaler-id og andre transskriptionskonventioner osv.


