
Kunstig intelligens og Big Data har potentialet til at finde løsninger på globale problemer, mens de prioriterer lokale problemer og transformerer verden på mange dybtgående måder. AI bringer løsninger til alle – og i alle sammenhænge, fra hjem til arbejdspladser. AI computere, med Maskinelæring træning, kan simulere intelligent adfærd og samtaler på en automatiseret, men personlig måde.
Alligevel står AI over for et inklusionsproblem og er ofte forudindtaget. Heldigvis med fokus på kunstig intelligens etik kan indvarsle nyere muligheder med hensyn til diversificering og inklusion ved at eliminere ubevidst bias gennem forskellige træningsdata.
Betydningen af mangfoldighed i AI-træningsdata
 Diversitet og kvalitet af træningsdata hænger sammen, da det ene påvirker det andet og påvirker resultatet af AI-løsningen. Succesen af AI-løsningen afhænger af forskelligartede data det trænes på. Datadiversitet forhindrer AI i at overtilpasse - hvilket betyder, at modellen kun udfører eller lærer af de data, der bruges til at træne. Med overfitting kan AI-modellen ikke give resultater, når den testes på data, der ikke bruges i træning.
Diversitet og kvalitet af træningsdata hænger sammen, da det ene påvirker det andet og påvirker resultatet af AI-løsningen. Succesen af AI-løsningen afhænger af forskelligartede data det trænes på. Datadiversitet forhindrer AI i at overtilpasse - hvilket betyder, at modellen kun udfører eller lærer af de data, der bruges til at træne. Med overfitting kan AI-modellen ikke give resultater, når den testes på data, der ikke bruges i træning.
Den nuværende tilstand af AI-træning data
Uligheden eller manglen på mangfoldighed i data ville føre til uretfærdige, uetiske og ikke-inklusive AI-løsninger, der kunne uddybe diskrimination. Men hvordan og hvorfor er mangfoldighed i data relateret til AI-løsninger?
Ulige repræsentation af alle klasser fører til forkert identifikation af ansigter – et vigtigt eksempel er Google Fotos, som klassificerede et sort par som "gorillaer". Og Meta spørger en bruger, der ser en video af sorte mænd, om brugeren gerne vil 'fortsætte med at se videoer af primater.'
For eksempel kan unøjagtig eller ukorrekt klassificering af etniske eller racemæssige minoriteter, især i chatbots, resultere i fordomme i AI-træningssystemer. Ifølge 2019-rapporten vedr Diskriminerende systemer – køn, race, magt i AI, mere end 80 % af lærere i kunstig intelligens er mænd; kvindelige AI-forskere på FB udgør kun 15 % og 10 % på Google.
Indvirkningen af forskellige træningsdata på AI-ydeevne
 At udelade specifikke grupper og fællesskaber fra datarepræsentation kan føre til skæve algoritmer.
At udelade specifikke grupper og fællesskaber fra datarepræsentation kan føre til skæve algoritmer.
Databias introduceres ofte ved et uheld i datasystemerne - ved at undersample bestemte racer eller grupper. Når ansigtsgenkendelsessystemer trænes på forskellige ansigter, hjælper det modellen med at identificere specifikke træk, såsom positionen af ansigtsorganer og farvevariationer.
Et andet resultat af at have en ubalanceret frekvens af etiketter er, at systemet måske betragter en minoritet som en anomali, når det presses til at producere et output inden for kort tid.
At opnå mangfoldighed i AI-træningsdata
På bagsiden er det også en udfordring at generere et mangfoldigt datasæt. Den rene mangel på data om visse klasser kan føre til underrepræsentation. Det kan afbødes ved at gøre AI-udviklerteamene mere forskellige med hensyn til færdigheder, etnicitet, race, køn, disciplin og mere. Desuden er den ideelle måde at løse problemer med datadiversitet i AI på at konfrontere det fra begyndelsen i stedet for at forsøge at rette op på det, der er gjort – at tilføre mangfoldighed på dataindsamlings- og kurationsstadiet.
Uanset hypen omkring AI, afhænger det stadig af de data, der indsamles, udvælges og trænes af mennesker. Den medfødte bias hos mennesker vil afspejle sig i de data, de indsamler, og denne ubevidste bias kryber også ind i ML-modellerne.
Trin til at indsamle og kurere forskellige træningsdata
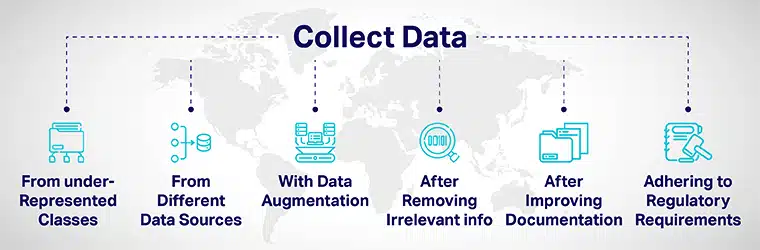
Datadiversitet kan opnås ved:
- Tilføj omhyggeligt flere data fra underrepræsenterede klasser og udsæt dine modeller for forskellige datapunkter.
- Ved at indsamle data fra forskellige datakilder.
- Ved dataforøgelse eller kunstig manipulation af datasæt for at øge/inkludere nye datapunkter, der er tydeligt forskellige fra de oprindelige datapunkter.
- Når du ansætter ansøgere til AI-udviklingsprocessen, skal du fjerne alle job-irrelevante oplysninger fra ansøgningen.
- Forbedring af gennemsigtighed og ansvarlighed ved at forbedre dokumentation for udvikling og evaluering af modeller.
- Indførelse af regler for at opbygge mangfoldighed og inklusivitet i AI systemer fra græsrodsniveau. Forskellige regeringer har udviklet retningslinjer for at sikre mangfoldighed og afbøde AI-bias, der kan levere urimelige resultater.
[Læs også: Lær mere om AI-træningsdataindsamlingsprocessen ]
Konklusion
I øjeblikket er kun få store teknologivirksomheder og læringscentre udelukkende involveret i at udvikle AI-løsninger. Disse eliterum er gennemsyret af eksklusion, diskrimination og partiskhed. Det er imidlertid disse rum, hvor AI udvikles, og logikken bag disse avancerede AI-systemer er fyldt med den samme skævhed, diskrimination og udelukkelse, som bæres af de underrepræsenterede grupper.
Mens man diskuterer mangfoldighed og ikke-diskrimination, er det vigtigt at stille spørgsmålstegn ved de mennesker, det gavner, og dem det skader. Vi bør også se på, hvem det stiller til ulempe – ved at fremtvinge ideen om en 'normal' person, kan AI potentielt sætte 'andre' i fare.
At diskutere mangfoldighed i AI-data uden at anerkende magtforhold, retfærdighed og retfærdighed vil ikke vise det større billede. For fuldt ud at forstå omfanget af mangfoldighed i AI-træningsdata, og hvordan mennesker og AI sammen kan afbøde denne krise, nå ud til ingeniørerne hos Shaip. Vi har forskellige AI-ingeniører, som kan levere dynamiske og forskelligartede data til dine AI-løsninger.


