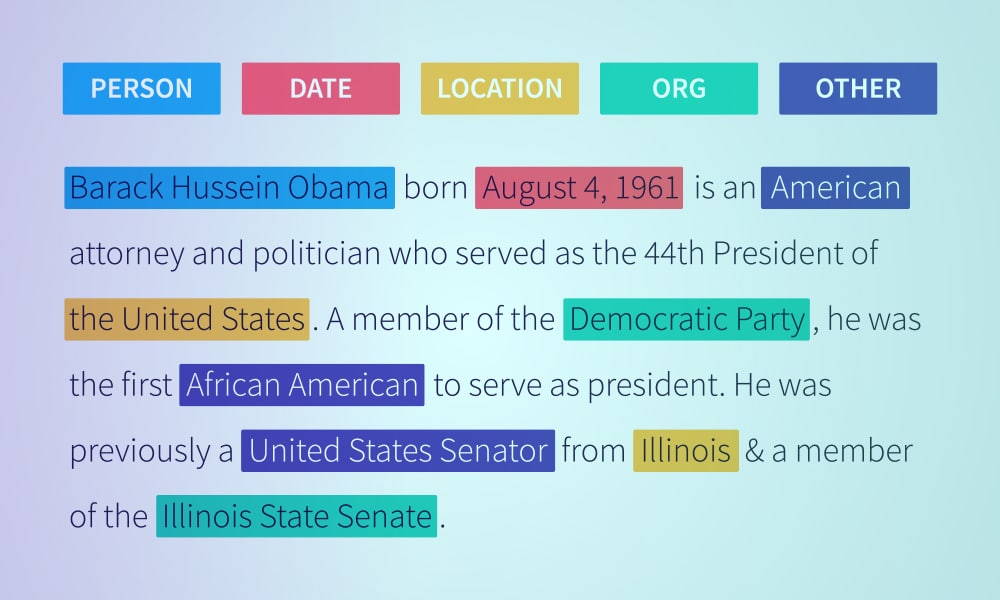
Data er supermagten, der transformerer det digitale landskab i nutidens verden. Fra e-mails til opslag på sociale medier er der data overalt. Det er rigtigt, at virksomheder aldrig har haft adgang til så meget data, men er det nok at have adgang til data? Den rige informationskilde bliver ubrugelig eller forældet, når den ikke behandles.
Ustruktureret tekst kan være en rig kilde til information, men den vil ikke være nyttig for virksomheder, medmindre dataene er organiseret, kategoriseret og analyseret. Ustrukturerede data, såsom tekst, lyd, videoer og sociale medier, udgør 80 -90% af alle data. Desuden er det angiveligt, at knap 18 % af organisationerne udnytter deres organisations ustrukturerede data.
Manuel sigtning gennem terabyte af data, der er gemt på serverne, er en tidskrævende og ærlig talt umulig opgave. Men med fremskridt inden for maskinlæring, naturlig sprogbehandling og automatisering er det muligt at strukturere og analysere tekstdata hurtigt og effektivt. Det første trin i dataanalyse er tekstklassificering.
Hvad er tekstklassificering?
Tekstklassificering eller kategorisering er processen med at gruppere tekst i forudbestemte kategorier eller klasser. Ved at bruge denne maskinlæringstilgang kan evt tekst – dokumenter, webfiler, undersøgelser, juridiske dokumenter, medicinske rapporter og mere – kan klassificeres, organiseres og struktureres.
Tekstklassificering er det grundlæggende trin i behandling af naturligt sprog, der har flere anvendelser i spam-detektion. Følelsesanalyse, hensigtsdetektion, datamærkning og mere.
Mulige anvendelsestilfælde af tekstklassificering
 Der er flere fordele ved at bruge maskinlæringstekstklassificering, såsom skalerbarhed, analysehastighed, konsistens og evnen til at træffe hurtige beslutninger baseret på samtaler i realtid.
Der er flere fordele ved at bruge maskinlæringstekstklassificering, såsom skalerbarhed, analysehastighed, konsistens og evnen til at træffe hurtige beslutninger baseret på samtaler i realtid.
Når ML-modellen er trænet i AI, der automatisk kategoriserer varer under forudindstillede kategorier, kan du hurtigt konvertere afslappede browsere til kunder.
Tekstklassificeringsproces
Tekstklassificeringsprocessen starter med forbehandling, funktionsvalg, udtrækning og klassificering af data.

Forbehandling
Tokenisering: Tekst er opdelt i mindre og enklere tekstformer for nem klassificering.
Normalisering: Al tekst i et dokument skal være på samme niveau af forståelse. Nogle former for normalisering omfatter,
- Opretholdelse af grammatiske eller strukturelle standarder på tværs af teksten, såsom fjernelse af hvide mellemrum eller tegnsætninger. Eller bevare små bogstaver i hele teksten.
- Fjernelse af præfikser og suffikser fra ord og bringe dem tilbage til deres rodord.
- Fjernelse af stopord som 'og' 'er' 'den' og flere, der ikke tilføjer værdi til teksten.
Funktionsvalg
Funktionsvalg er et grundlæggende trin i tekstklassificering. Processen er rettet mod at repræsentere tekster med det mest relevante træk. Funktionsvalg hjælper med at fjerne irrelevante data og forbedre nøjagtigheden.
Funktionsvalg reducerer inputvariablen i modellen ved kun at bruge de mest relevante data og eliminere støj. Baseret på den type løsning, du søger, kan dine AI-modeller designes til kun at vælge de relevante funktioner fra teksten.
Funktion ekstraktion
Funktionsudtrækning er et valgfrit trin, som nogle virksomheder påtager sig for at udtrække yderligere nøglefunktioner i dataene. Funktionsudtrækning bruger flere teknikker, såsom kortlægning, filtrering og klyngedannelse. Den primære fordel ved at bruge funktionsekstraktion er – det hjælper med at fjerne overflødige data og forbedre hastigheden, hvormed ML-modellen udvikles.
Tagning af data til forudbestemte kategorier
Tagning af tekst til foruddefinerede kategorier er det sidste trin i tekstklassificering. Det kan gøres på tre forskellige måder,
- Manuel tagging
- Regelbaseret matchning
- Læringsalgoritmer – Indlæringsalgoritmerne kan yderligere klassificeres i to kategorier, såsom overvåget tagging og uovervåget tagging.
- Superviseret læring: ML-modellen kan automatisk justere tags med eksisterende kategoriserede data i overvåget tagging. Når kategoriserede data allerede er tilgængelige, kan ML-algoritmerne kortlægge funktionen mellem tags og tekst.
- Uovervåget læring: Det sker, når der er mangel på tidligere eksisterende taggede data. ML-modeller bruger clustering og regelbaserede algoritmer til at gruppere lignende tekster, f.eks. baseret på produktkøbshistorik, anmeldelser, personlige oplysninger og billetter. Disse brede grupper kan analyseres yderligere for at tegne værdifuld kundespecifik indsigt, som kan bruges til at designe skræddersyede kundetilgange.
Der er flere use cases for tekstklassificering på tværs af brancher. Selvom indsamling, gruppering, klassificering og udtrækning af værdifuld indsigt fra tekstdata altid har været brugt på flere områder, finder tekstklassificering sit potentiale inden for markedsføring, produktudvikling, kundeservice, ledelse og administration. Det hjælper virksomheder med at få konkurrencedygtig intelligens, markeds- og kundekendskab og træffe databaserede forretningsbeslutninger.
Det er ikke let at udvikle et effektivt og indsigtsfuldt tekstklassificeringsværktøj. Alligevel kan du med Shaip som din datapartner udvikle et effektivt, skalerbart og omkostningseffektivt AI-baseret tekstklassificeringsværktøj. Vi har tonsvis af præcist kommenterede og klar til brug datasæt der kan tilpasses til din models unikke krav. Vi gør din tekst til en konkurrencefordel; kontakt i dag.