
Hvad er tekstanmærkning i maskinlæring?
Tekstannotering i maskinlæring refererer til tilføjelse af metadata eller etiketter til rå tekstdata for at skabe strukturerede datasæt til træning, evaluering og forbedring af maskinlæringsmodeller. Det er et afgørende trin i NLP-opgaver (natural language processing), da det hjælper algoritmer med at forstå, fortolke og lave forudsigelser baseret på tekstinput.
Tekstannotering er vigtig, fordi den hjælper med at bygge bro mellem ustrukturerede tekstdata og strukturerede, maskinlæsbare data. Dette gør det muligt for maskinlæringsmodeller at lære og generalisere mønstre fra de kommenterede eksempler.
Annoteringer af høj kvalitet er afgørende for at bygge nøjagtige og robuste modeller. Dette er grunden til, at omhyggelig opmærksomhed på detaljer, konsistens og domæneekspertise er afgørende i tekstannotering.
Typer af tekstanmærkninger

Når du træner NLP-algoritmer, er det vigtigt at have store annoterede tekstdatasæt, der er skræddersyet til hvert projekts unikke behov. Så for udviklere, der ønsker at oprette sådanne datasæt, er her en simpel oversigt over fem populære tekstanmærkningstyper.

Følelse af stemning
Følelsesannotering identificerer en teksts underliggende følelser, meninger eller holdninger. Annotatorer mærker tekstsegmenter med positive, negative eller neutrale følelser-tags. Følelsesanalyse, en nøgleanvendelse af denne annoteringstype, bruges i vid udstrækning i overvågning af sociale medier, analyse af kundefeedback og markedsundersøgelser.
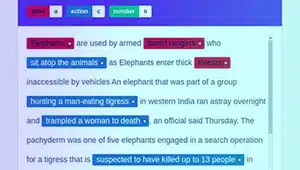
Intent annotation
Hensigtsanmærkning har til formål at fange formålet eller målet bag en given tekst. I denne type annotering tildeler annotatorer etiketter til tekstsegmenter, der repræsenterer specifikke brugerhensigter, såsom at bede om information, anmode om noget eller udtrykke en præference.
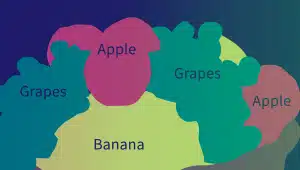
Semantisk kommentar
Semantisk annotering identificerer betydningen og relationerne mellem ord, sætninger og sætninger. Annotatorer bruger forskellige teknikker, såsom tekstsegmentering, dokumentanalyse og tekstudtrækning, til at mærke og klassificere tekstelementers semantiske egenskaber.

Enhedskommentar
Enhedsannotering er afgørende for at skabe chatbot-træningsdatasæt og andre NLP-data. Det involverer at finde og mærke enheder i tekst. Typer af enhedsannoteringer omfatter:

Sproglig annotering
Sproglig annotering omhandler de strukturelle og grammatiske aspekter af sprog. Det omfatter forskellige underopgaver, såsom orddeltagging, syntaktisk parsing og morfologisk analyse.

Forsikring
Tekstannotering hjælper forsikringsselskaber med at analysere kundefeedback, behandle krav og opdage svindel. Ved at bruge AI-modeller, der er trænet på annoterede datasæt, kan forsikringsselskaberne:

Bank
Tekstanmærkning letter forbedret kundeservice, opdagelse af svindel og dokumentanalyse i bankvirksomhed. AI-systemer trænet på annoterede data kan:

Telecom
Tekstannotering gør det muligt for teleselskaber at forbedre kundesupport, overvåge sociale medier og administrere netværksproblemer. Maskinlæringsmodeller trænet på annoterede datasæt kan:
Hvordan kommenterer man tekstdata?
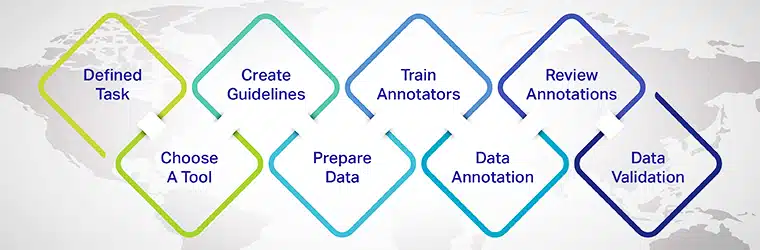
- Definer anmærkningsopgaven: Bestem den specifikke NLP-opgave, du vil løse, såsom følelsesanalyse, navngiven enhedsgenkendelse eller tekstklassificering.
- Vælg et passende anmærkningsværktøj: Vælg et tekstanmærkningsværktøj eller -platform, der opfylder dine projektkrav og understøtter de ønskede anmærkningstyper.
- Opret annoteringsretningslinjer: Udvikl klare og konsistente retningslinjer for annotatorer at følge, og sikring af høj kvalitet og nøjagtige annoteringer.
- Vælg og klargør dataene: Saml et mangfoldigt og repræsentativt udsnit af rå tekstdata, som annotatorerne kan arbejde videre med.
- Træn og evaluer annotatorer: Give uddannelse og løbende feedback til annotatorer, hvilket sikrer konsistens og kvalitet i annoteringsprocessen.
- Anmærk dataene: Annotatorer mærker teksten i henhold til de definerede retningslinjer og anmærkningstyper.
- Gennemgå og finjuster annoteringer: Gennemgå og finpuds jævnligt annoteringerne, korriger eventuelle uoverensstemmelser eller fejl og forbedrer datasættet iterativt.
- Opdel datasættet: Opdel de annoterede data i trænings-, validerings- og testsæt for at træne og evaluere maskinlæringsmodellen.
Hvad kan Shaip gøre for dig?
Shaip tilbyder skræddersyet løsninger til tekstkommentarer til at drive dine AI- og maskinlæringsapplikationer i forskellige brancher. Med et stærkt fokus på højkvalitets og præcise annoteringer kan Shaips erfarne team og avancerede annotationsplatform håndtere forskelligartede tekstdata.
Uanset om det er sentimentanalyse, navngivet enhedsgenkendelse eller tekstklassificering, leverer Shaip tilpassede datasæt til at hjælpe med at forbedre dine AI-modellers sprogforståelse og ydeevne.
Stol på Shaip for at strømline din tekstanmærkningsproces og sikre, at dine AI-systemer når deres fulde potentiale.

