
I vores digitale verden behandler virksomheder tonsvis af data dagligt. Data holder organisationen kørende og hjælper den med at træffe bedre informerede beslutninger. Virksomheder oversvømmes med dokumenter, lige fra medarbejdere, der opretter nye til dokumenter, der kommer ind i organisationen fra forskellige kilder såsom e-mails, portaler, fakturaer, kvitteringer, ansøgninger, forslag, krav og mere.
Medmindre nogen gennemgår disse dokumenter, er der ingen måde at vide, hvad et bestemt dokument handler om, eller den bedste måde at behandle det på. Det er dog svært at manuelt behandle hvert dokument for at vide, hvor og hvordan det skal opbevares.
Lad os udforske dokumentklassificering, forstå, hvorfor dokumentklassificering er afgørende for en virksomhed, og studere, hvordan computersyn, naturlig sprogbehandling og optisk tegngenkendelse spiller en rolle i dokumentklassificering eller dokumentbehandling.
Hvad er dokumentklassificering?
Manuelle dokumentklassificeringsopgaver kan være en stor flaskehals for mange virksomheder, da de er tidskrævende, fejludsatte og ressourcekrævende. Når der anvendes automatiske klassifikationsmodeller baseret på NLP og ML, identificeres, tagges og kategoriseres teksten i et dokument automatisk.
Dokumentklassificeringsopgaver er generelt baseret på to klassifikationer: tekst og visuel. Tekstklassificering er baseret på indholdets genre, tema eller type. Natural Language Processing bruges til at forstå tekstens koncept, følelser og kontekst. Visuel klassificering udføres baseret på de visuelle strukturelle elementer, der er til stede i dokumentet, ved hjælp af Computer Vision og billedgenkendelsessystemer.
Hvorfor kræver virksomheder dokumentklassificering?

Enhver virksomhed, stor som lille, skal håndtere dokumentation for at styre sin daglige drift. Da det er umuligt at behandle hvert dokument manuelt, er det nødvendigt at anvende et automatisk dokumentklassifikationssystem. Dokumentklassificeringssystemet giver virksomheder mulighed for at organisere indhold og gøre det tilgængeligt når som helst.
Dokumentklassificering har flere use cases i forskellige brancher, fra hospitaler til virksomheder.
- Det hjælper virksomheder med at automatisere dokumenthåndtering og -behandling.
- Dokumentklassificering er en hverdagsagtig og gentagne opgave, automatisering af processen reducerer behandlingsfejl og forbedrer ekspeditionstiden.
- Automatisering af dokumenter forbedrer også effektivitet, pålidelighed og skalerbarhed.
Dokumentklassificering vs. Tekstklassificering
Tekstklassificering og dokumentklassificering bruges nogle gange i flæng. Selvom der er en meget lille forskel mellem de to, er det vigtigt at vide, hvordan de adskiller sig.
Tekstklassificering handler om at anvende teknikker til at analysere tekst i tekstbaserede dokumenter. Teksten kan klassificeres på forskellige niveauer, som f.eks
| Sætningsniveau | Undersætningsniveau |
|---|---|
| Tekstklassificeringen er baseret på oplysningerne i en enkelt sætning. | Undersætningsniveauet trækker underudtryk inde fra sætninger. |
| Afsnitsniveau | Dokumentniveau |
|---|---|
| Uddrager den centrale eller mest kritiske information fra et enkelt afsnit. | Tegn vigtig information fra hele dokumentet. |
Tekstklassificering er en undergruppe af dokumentklassificering, der udelukkende beskæftiger sig med klassificering af teksten i et givet dokument. Mens tekstklassificering kun omhandler teksten, dokumentklassificering er både tekstuel og visuel. I tekstklassificering bruges kun teksten til at klassificere, hvorimod i dokumentklassificering kan det komplette dokument bruges til kontekst.
Hvordan fungerer dokumentklassificering?
Dokumentklassificering kan udføres ved hjælp af to metoder: manuel og automatisk. Ved manuel klassificering skal en menneskelig bruger gennemgå dokumenter, finde sammenhænge mellem begreber og kategorisere i overensstemmelse hermed. Ved automatisk dokumentklassificering anvendes maskinlæring og deep learning-teknikker. Lad os optrevle dokumentklassificeringsmetoder ved at forstå de forskellige typer dokumenter, som en virksomhed behandler.
Strukturerede dokumenter
Et dokument indeholder velformaterede data med ensartet nummerering og skrifttyper. Layoutet af dokumentet er også konsistent og har ingen afvigelser. Det er nemt og forudsigeligt at bygge klassifikationsværktøjer til sådanne strukturerede dokumenter.
Ustrukturerede dokumenter
Et ustruktureret dokument har indhold præsenteret i et ikke-struktureret eller åbent format. Eksempler omfatter breve, kontrakter og ordrer. Da de er inkonsistente, bliver det udfordrende at lokalisere kritisk information.

Dokumentklassificeringsteknikker?
Automatisk dokumentklassificering bruger Machine Learning og Natural Language Processing-teknikker til at forenkle, automatisere og fremskynde kategoriseringsprocessen. Maskinlæring gør dokumentklassificering mindre besværlig, hurtigere, mere nøjagtig, skalerbar og upartisk.
Dokumentklassificering kan udføres ved hjælp af tre teknikker. De er
Regelbaseret teknik
Den regelbaserede teknik er baseret på sproglige mønstre og regler, der giver instruktioner til modellen. Modellerne er trænet til at identificere sprogmønstre, morfologi, syntaks, semantik og mere til at mærke teksten. Denne teknik kan konstant forbedres, nye regler tilføjes og improviseres for at udtrække nøjagtige indsigter. Denne teknik kan dog være tidskrævende, uskalerbar og kompleks.
Overvåget læring
Et sæt tags er defineret i overvåget læring, og flere tekster er manuelt tagget, så maskinlæringssystemet kan lære at lave præcise forudsigelser. Algoritmen trænes manuelt på et sæt mærkede dokumenter. Jo flere data du indlæser i systemet, jo bedre bliver resultatet. Hvis teksten f.eks. siger "Tjenesten var overkommelig", skal tagget stå under "prissætning". Når modellens træning er afsluttet, kan den automatisk forudsige usete dokumenter.
Uovervåget læring
I uovervåget læring er lignende dokumenter grupperet i forskellige klynger. Denne læring kræver ingen forudgående viden. Dokumenterne er kategoriseret baseret på skrifttyper, temaer, skabeloner og mere. Hvis reglerne er foruddefinerede, tweakede og perfektionerede, kan denne model levere klassificering med nøjagtighed.
Dokumentklassificeringsproces
Opbygning af en automatiseret dokumentklassificeringsalgoritme involverer dyb læring og maskinlæringsarbejdsgange.
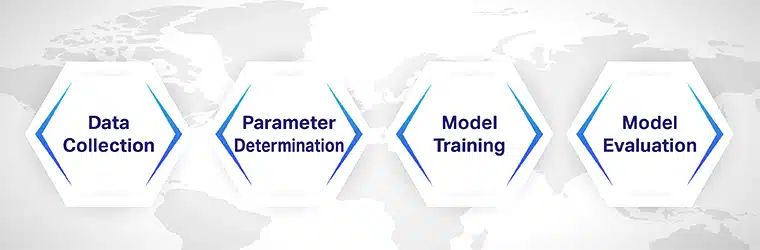
Trin 1: Dataindsamling
Dataindsamling er måske det mest afgørende trin i træning af dokumentklassificeringsalgoritmer. Det er nødvendigt at samle dokumenter fra forskellige kategorier, så algoritmen kan lære at klassificere dem.
For eksempel, hvis din model skal klassificeres i fem forskellige kategorier, skal du have et datasæt indeholdende minimum 300 dokumenter pr. kategori.
Sørg også for, at det datasæt, du bruger til træningen, er korrekt tagget. Hvis datasættet er forkert, vil den model, du bygger, være fyldt med problemer.
Trin 2: Parameterbestemmelse
Før du træner modellen, skal du bestemme parametrene for at træne maskinlæringsmodellerne. De metrics, du definerer på dette stadium, kan ændres for at gøre modellen mere nøjagtig og pålidelig i sine forudsigelser.
Trin 3: Modeltræning
Efter indstilling af parametrene skal modellen trænes. Hvis du lige er startet med modeludvikling, kan du prøve at bruge open source-datasæt til trænings- og testformål.
Hvis modellen typisk arbejder med en maskinlæringsalgoritme, kan du importere modellen eller udføre kodning baseret på algoritmens logik.
Trin 4: Modelvurdering
Evaluering af modellen efter træningen er afgørende for at øge dens effektivitet og nøjagtighed. Begynd med at opdele datasættet i to brede sektioner, en til træning og den anden til test. Brug 70 % af datasættet til træning af modellen, og resten, 30 %, til test og evaluering.
Virkelige brugssager
Dokumentklassificering bliver brugt til at løse flere forretningsproblemer. Selvom de fleste use cases ikke er klassifikationsopgaver, finder algoritmen sig selv ansat til at løse flere virkelige problemer.
Spam detektion
Dokumentklassificering, især tekstklassificering, bruges til at opdage uønsket spam. Modellen er trænet til at opdage spam-sætninger og deres hyppighed for at afgøre, om beskeden er spam. For eksempel bruger Googles Gmail Spam-detektor Natural Language Processing-teknikken til at registrere hyppigt forekommende ord i uønskede meddelelser og slippe e-mailen i den korrekte mappe.
Følelsesanalyse
Følelsesanalyse gennem social lytning hjælper virksomheder med at forstå deres kunder, deres meninger og deres anmeldelser. Ved at klassificere anmeldelser, feedback og klager og kategorisere dem baseret på deres følelsesmæssige natur, hjælper de NLP-baserede modeller med sentimentanalyse. Modellen er trænet i at udtrække ord, der betegner eller har positive eller negative konnotationer.
Billet eller prioriteret klassifikation
Enhver virksomheds kundeserviceafdeling støder på mange serviceanmodninger og billetter. Et automatiseret dokumentklassificeringsværktøj kan hjælpe med at vade gennem den enorme mængde af billetter. Ved hjælp af NLP kan prioritetsbilletter dirigeres til den rigtige afdeling. Dette forbedrer hastigheden for opløsning, behandling og service markant.
Objektgenkendelse
Automatiseret dokumentklassificering bruges også til at behandle store mængder visuelle data i dokumenter ved at klassificere dem efter kategorier. Objektgenkendelse bruges typisk i e-handel eller produktionsenheder til at klassificere produkter.
Kom godt i gang med dokumentklassificering drevet af AI
Dokumenter indeholder data, der er kritiske for virksomhedens funktion. Dokumenterne indeholder værdifuld indsigt, der fremmer en organisations drift, tjenester og vækstmål.
Klassificering af dokumenter er dog en kedelig, men nødvendig opgave. Da dokumentklassificering er en udfordring, især hvis volumen er relativt høj, er det nødvendigt med et automatiseret dokumentklassifikationssystem.
En AI-baseret dokumentklassificeringsmodel trænet af maskinlæringsalgoritmer er effektiv, omkostningseffektiv, fejlfri og nøjagtig. Men processen kan kun starte, når den model, du bygger, er trænet i kvalitet og nøjagtigt taggede datasæt.
Shaip bringer til dig præ-taggede datasæt som hjælper med at udvikle nøjagtige klassifikationsmodeller. Kontakt os og kom i gang med dit dokumentklassificeringsværktøj med det samme.


